
In the end, the only area of human activity where I truly excel is in the organization of impromptu adventures while traveling. And there is no more fertile ground for this skill than the awkward night shoehorned between a late arrival in a new city and a following day of planned activities.
Arriving in Seattle from Portland on the 3:30 p.m. train as we did today was a prime example of this: all other things being equal we could have simply checked into our hotel, found a place to have supper, and then retired early after a day that was sedentary but somehow also exhausting.
But that is not my style.
So here’s what we did instead.
We did, indeed, take a cab to our hotel, a return engagement at the same Palihotel where we stayed on Tuesday night.
After dropping our bags and feeding and watering Ethan the Dog, we walked up the street to the Seattle showroom for the Tuft & Needle mattress-in-a-box company. I am confounded by mattress purchasing, and haunted by the memory of too much time spent in the basement at Leon’s being overwhelmed by choice and unable to get a true sense for how any given mattress will perform under daily use.
The mattress-in-a-box industry has a not unpleasant “we’re shaking things up and taking down Big Mattress” quality to it, but not being able to take their wares for a ride makes it similarly impossible to get a sense of whether their mattresses are actually any good for my body.
Enter the aforementioned showroom, which consists simply of four neo-rooms formed out of semi-transparent gauze, each outfitted with a mattress on which one is free to lay about and, relative to Leon’s et al, simulate day-to-day life. Tuft & Needle doesn’t ship to Canada, so the experiment was moot for our particular purposes, but it was pleasant to see things done differently, and the comfort of their beds gave me some hope that the made-in-Canada equivalent mattresses might work for me.
Thus-sated, we called an Uber and headed for Northwest Film Forum, in Capitol Hill, where I’d secured us tickets for Astra Taylor’s film What is Democracy?, a film that ticked our interests in both documentaries and politics.
We arrived with about an hour to spare, and so looked around the neighbourhood to see what we could see.
Oliver’s eagle eyes spotted a hair salon directly across the street that was, oddly, still open on a Sunday at 6:00 p.m. We poked our head in the door and found that they did, indeed, have a slot available for Oliver. And so he got his hair cut.
Twenty minutes later and freshly-shorn, we went looking for a place to eat and found a Poké Bar just up the street where we enjoyed bowls of rice, fish and seasonings along with iced jasmine tea.
We finished up supper just in time to walk across the street to the cinema, and got two seats in the second row, with a nook for Ethan to curl into right in front of us.
Northwest Film Forum is an interesting institution, equal parts film exhibition space and film school; the promos that ran during the pre-show revealed a collection of screenings and courses that would have made me comfortable renting an apartment nearby and dropping by every day.
What is Democracy?, as the title suggests, is an extended rumination on democracy. It is neither a class in civics nor a polemic, but rather a holding up of the sphere of democracy to the light, through the eyes of everyone from Cornell West to Miami school students to Syrian refugees living on the docks in Greece. It was heady stuff, and made all the more heady by a fellow audience member who started to yell out dissenting views early on and, when shushed by others, became militantly anti-social and was expelled from the theatre while yelling a series of epithets about how we who remained were sheep-like white people being lured into a cult.
The irony of the interruption in the context of the subject matter was not lost, but there was a significant collective sigh of relief when calm returned, as things could have easily gone further sideways.
The film was followed by a brief Q&A with the director, who was engaging and thoughtful.
When it was all done we piled into another Uber and were back in our hotel by 9:45 p.m., ready for bed and anticipating a final day of vacation adventuring in Seattle tomorrow.
Friday morning in Portland we decided that we wanted to experiment with driving a car2go car, and a desire to visit a Best Buy in the suburbs to look at phones presented a conceit.
We’d previously rented car2go cars in Montreal, where the fleet is almost entirely tiny Smart cars; here in Portland, though, they only use full-sized Mercedes, the likes of which my caste doesn’t allow me to drive otherwise, so there was an added bonus. The rental process was painless: find a nearby car on the app (a block from our hotel), tap its icon, enter the code on the car’s dash and, presto, it’s remotely unlocked, with the key in the glove box.

We drove out of central Portland and into the hills, found the Best Buy, decided the phones on offer weren’t worthy, and drove back downtown and across the river to leave the car and go to OMSI, the Oregon Museum of Science and Industry.
The Achilles heel of using a car2go car is that you need to find a place to park it when you’re done. In theory this should be easy, as any legal street parking spot with allowance of more than 2 hours is eligible. But spots near OMSI were in short supply, so we ended up touring the neighbourhood for 15 minutes before we found a spot. This was not for nought, however, as the walk to OMSI then took us by Sushi Mazi, where we stopped for an excellent lunch.
After lunch we walked through a light rain to OMSI, just 10 minutes away. The museum itself proved disappointing: while the temporary exhibit about the making of Pixar films taught us a few new things, the rest of the museum was tired, interesting exhibits were short on the vine, and the whole place was chaotic, as it was filled to the brim with agitated school break campers. We cut our visit a little short, which didn’t hurt too much, as we’d only paid $10 to enter, leveraging Oliver’s Discovery Centre membership, with its reciprocal admission privileges, for our entry, paying only for the Pixar add-on.

From OMSI we took the train one stop across the Tilikum Crossing Bridge to rendezvous with Oliver Baker; Portland’s transit system is Scandinavian-level good, with simple fare structure, easy payment with a tap, and intermodal transfers.
On the other side we had a snack of tacos at Cha Cha Cha, bought some dog food for Ethan from a local joint and then, once Oliver B. arrived, we rode the gondola that connects the riverside and hilltop parts of the Oregon Health Sciences University campus together; as I’m a fan of gondolas and funiculars, this was lots of fun.

The hillside campus at the top was shiny, modern, and pleasantly art-filled.


After a ride back down to the riverside, we walked back across the bridge and stopped in for a quick visit at the Oregon Rail Heritage Center; our time was limited, as they were about to close, but it was a good visit nonetheless, and we learned a lot about how locomotives work (knowledge that serves me well as I type this post on the train north to Seattle).
We grabbed a snack at Boke Bowl, walked back across the river, and took Oliver’s car to his house for a follow-up snack for humans and dogs.
Our final adventure of the day was a showing of Captain Marvel at the lovely Moreland Theatre, which sported excellent popcorn, loganberry cider, and comfortable seats. Oliver B. dropped us back to our hotel around 11:00 p.m. where we retired to bed almost immediately given our fun-filled program for the day.

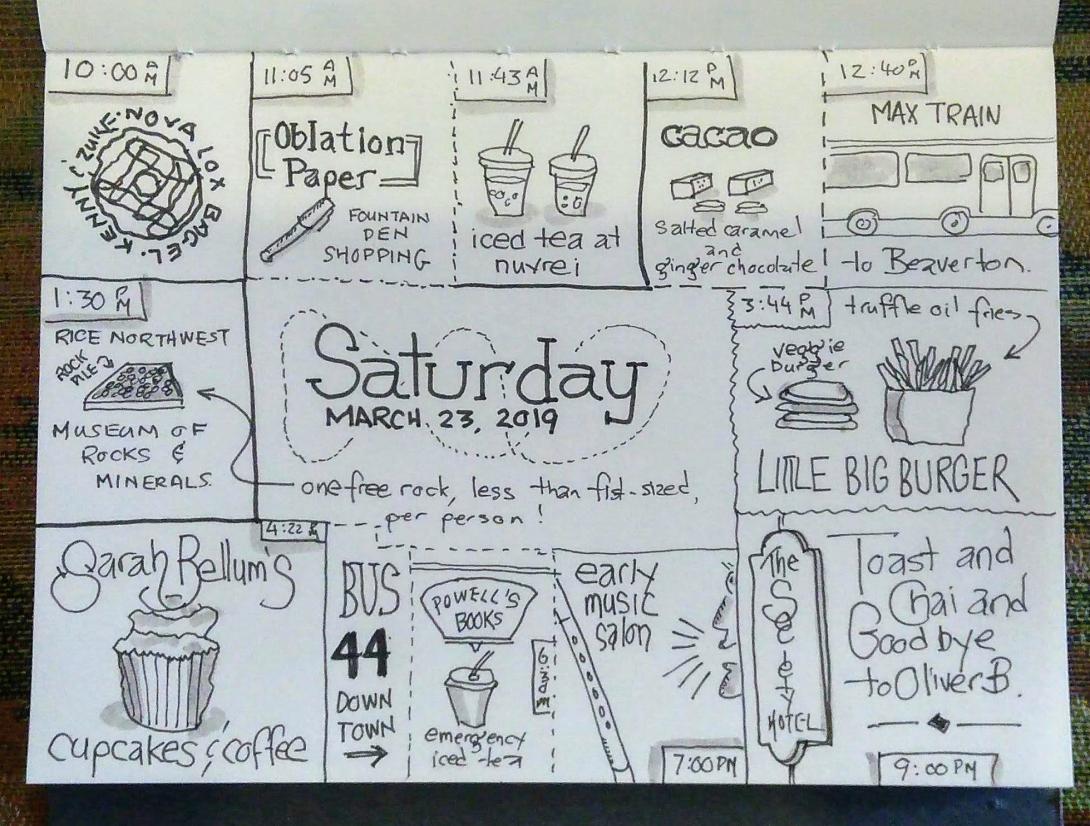
The Rice Northwest Museum of Rocks & Minerals is located in a purpose-built ranch-style house west of Portland.
The washroom near the phosphorescence room is a bona fide residential washroom, in resplendent pink, complete with shower, tub, and dual sinks.
And an Automatic Bathroom Ventilator.

Our friend Oliver took this photo of us yesterday as we were walking over the Tilikum Crossing Bridge in Portland.

As related earlier, we did not take the direct route from Charlottetown to Portland: we left Charlottetown on Monday afternoon, and arrived Portland late on Wednesday evening, more than 48 hours later. But along the way we got to see several old friends, ate some good meals, drank some good coffee, and got microdoses of two cities we hadn’t visited in a long while.
But arrive in Portland we did, last night just after 10:00 p.m., on the Amtrak Cascades train from Seattle. We navigated our way through the deserted and foreboding streets of Old Town and checked into our lovely, minimalist room at The Society Hotel.
We’ve been gradually adjusting to the four hour time zone difference between PEI and the west coast, and this morning we didn’t wake up until 8:30 a.m., which means we’ve come close to reaching a new equilibrium. We ventured out into our new neighbourhood, stopping first in the park by the river to all Ethan to pee, then to Deadstock Coffee, and finally to Mothers Bistro for breakfast.
Fully sated, we then walked up the street to Powell’s Books, suitably overwhelming (most impressive infrastructural feature is a magic-seeming elevator with three doors); I emerged with a foot-high pile of books about type, bookbinding and fashion design (I sense a visit to the post office will be needed). By the time we were ready to leave my friend Oliver–our reason for visiting Portland in the first place–appeared at the end of aisle 939 as appointed, and we headed off with him for an afternoon of adventuring.
Said adventures included a stop at Nuvrei for iced tea and cookies, shoe shopping at Keen and REI (see [wee] Oliver’s new shoes below; they’re made of wool), and a visit to the dog park (where Ethan displayed his typical “you don’t have me on a leash; why is it in my best interests to come when you call me” confounding behaviour).
After a pit stop at Oliver’s house, we rendezvoused with Oliver’s sweetheart Cheryl for a excellent Indian meal at Swagat.
And now we’re hunkered down at our hotel, enjoying our first early evening this week.
This trip has a whirlwind character to it, and we’re certainly in no danger of overstaying our welcome at any juncture; we couldn’t keep up this pace for weeks on end, but as a the-journey-is-the-destination trip it has a lot to recommend it.

 ,
, 
Valerie Bang-Jensen and her family are one of the great gifts this blog has given me. As it happened, Valerie’s visit to Seattle overlapped with ours, so we spent a very pleasant afternoon, with her and her daughter Bree, visiting Bainbridge Island.
We had great coffee, a vegan lunch, a visit with my colleagues at Quinn-Brein (complete with projection room tour in their multiplex) and a stunning ferry ride, in sunny 22°C weather, both ways.
Valerie took this photo of our crew.

Public Service Announcement: the CleanTalk service I use to trap comment spam gete is breaking and you will more likely than not encounter protest if you try to comment. I’m on it.
On the way down to the elevator in our hotel this morning I mentioned to Oliver that we were going to get coffee in a building where Amazon also has offices.
“Be careful what you say,” he said, “and don’t mention the New York situation.”
“You mean if we’re talking to anyone who works for Amazon?”, I asked.
“Yes, if you see any Amazonians,” he replied.
“I’m not sure that’s what they’re called,” I told him.
The woman in front of us in the line for the elevator turned around and said, smiling, “Yes, that’s what we’re called.”
We then had a pleasant chat on the way down about what we should see and do in Seattle.
Once we parted company, and were walking down the street en route to coffee, Oliver exhaled and said “Well, that was awkward.”

About This Blog
 I am Peter Rukavina and this is my blog. I am a writer, letterpress printer, and a curious person.
I am Peter Rukavina and this is my blog. I am a writer, letterpress printer, and a curious person.
To learn more about me, read my /now, look at my bio, listen to audio I’ve posted, read presentations and speeches I’ve written, see things I’ve favourited elsewhere, or get in touch (peter@rukavina.net is the quickest way).
I have been writing here since May 1999: you can explore the 25+ years of blog posts in the archive.
![]() You can subscribe to an RSS feed of posts, an RSS feed of comments, an RSS feed of favourites elsewhere, or a podcast RSS feed that just contains audio posts. You can also receive a daily digests of posts by email. I also publish an OPML blogroll.
You can subscribe to an RSS feed of posts, an RSS feed of comments, an RSS feed of favourites elsewhere, or a podcast RSS feed that just contains audio posts. You can also receive a daily digests of posts by email. I also publish an OPML blogroll.
Instagram • YouTube • Vimeo • ORCID • OpenStreetMap • Internet Archive • PEI.art • Drupal • Github.