
For as long as I can remember – for as long as avatars have been a part of the Internet – the visual representation of “me online” has been a photo I took a decade ago, in July of 2003, and then applied a whole lotta red to. I appreciated the photo for its slight hint of whimsy and for its ability to stand out in a forest of avatars. But this morning it suddenly struck me as “so 2003” and I resolved to update it.
Thanks to iPhoto’s automated face-detection, I had a lot of pictures of myself to choose from, 387 in all:

Alas I couldn’t find one I liked: once I eliminated the fuzzy ones, and the ones that made me look puffy, and the ones where I was wearing glasses that seem to be from 1974 and the ones where I had an unfortunate haircut, there wasn’t much left.
Fortunately I found the answer on Flickr’s Photos of Peter page.
Four years ago at the last reboot conference, in June of 2009, Alper Çuğun took a photo of me that I’ve always liked: it wasn’t posed, I had one of the best haircuts of my life, and, well, Alper takes a good photo:

I’m also wearing a slightly whimsical look – am I about to laugh? – that I like. So I took that photo – generously made available by Alper under a Creative Commons license that allows me to re-use and adapt it – and cropped out a chunk of it, and the end result is this:
![]()
With new avatar in hand, I set about updating the Internet. There are likely hundreds and hundreds of places of scattered ye olde avatar around the net, but fortunately there are a 5 or 6 places where it’s seen a lot that were easy to update:
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Oh, and that “header photo” that you see in several of those screen shots above? It’s one I took in the Vitra Design Museum several years ago, near dusk, looking up at the sky out of the central courtyard of the main pavilion.
If you’d like to update your address books, instant messenger clients and so on, here’s a selection of sizes of the new avatar:
|
16x16 |
32x32 |
57x57 |
64x64 |
|
72x72 |
80x80 |
96x96 |
128x128 |
I expected the day to start with a small meeting – perhaps 3 or 4 people – around a table at Casa Mia Café: “teacher agent of change” Bonnie Bracey Sutton is in Charlottetown for the StopCyberbullying Youth Summit and I thought it would be good for our PEI Home and School Technology Committee to meet with her to share information and get her advice on how to forward the cause of educational technology in the province, a topic she is deeply versed in.
As it turned out this intimate meeting transformed before our very eyes into a sort of “A-Team” of smart, helpful experts in all things educational and digital: as our back table filled out I found myself in the company of Barbara Coloroso, Shadi Hayden, Allan McCullough, Parry Aftab, Kevin Harrison, and Sharon Rosenfeldt, along with my peers from Home and School, Shirley Jay, Chris Mears, and Heather Mullen. And, of course, Bonnie Bracey Sutton.
“How can we help?”, asked Parry.
I began by telling the story of TeacherNet, our project to outfit Prince Street Elementary School with wifi, a project that is a local success that we hope to spread to other schools.
I then laid out much the same tale as Frances Squire, Ben Boyle and Ghenyk McDonald told to The Guardian last week: we present Island students and teachers with a heavily filtered version of the Internet that renders it so much less than it can be, and leave them to use hand-me-down computers running a decade-old operating system that leaves them unable to experience many valuable tools and resources of the modern web. The end effect of which is to stymie much of the potential of the digital classroom.
“What can we do?”, I asked.
Their responses were universally supportive and practical.
No, you are not crazy, they told us: you’re facing the same challenges as digitally engaged parents, students and educators around the world. Keep at it.
You have allies, they told us: a bunch of smart students and adults, along with Google, Microsoft, Facebook, and LinkedIn will be here this weekend and we can rally them all to our cause, and shine light on the potential of Island schools with their help.
Shout about your successes, they told us: when a project like TeacherNet works, spread word of it far and wide.
And, perhaps most importantly, they each, to a person, confirmed my own belief that giving students agency in a digital era – rather than try to lock them inside leaky digital prisons – is not only the best way to engage them and to improve education outcomes, but it’s also, as it happens, the best way to counter cyberbullying.
Those around the table not only offered these wise words, but they offered to help us help those in a position to change policy and improve infrastructure understand the challenges and opportunities ahead: changing policy about technology, especially about filtering, is a significant step, and we need help making the case for these changes, and getting all concerned to understand the risks and rewards.
My fear going into this weekend’s StopCyberbullying Youth Summit was that I was going to be confronted by a philosophy that sought to address cyberbulling through the same “if we close the blinds we can pretend it’s not there” attitude that our education system manifests toward technology in general.
I thought I was going to meet people who wanted to build better filters, tighter firewalls, and to make the Internet even less of what it is in schools.
I was wrong.
Around that table of people who have thought long and hard about all of this was a surprising consensus: the way forward lies through giving students more control over the tending the digital ecosystem, not less.
I’m looking forward to diving deeper tomorrow; as it is, we have some new wind in our technology-advocating-sails, for which I owe a great debt of gratitude to all who sat around that table this morning.
In the fall of 1882 Oscar Wilde made a 9-stop tour of the Canadian Maritimes, a tour that brought him to Charlottetown on the evening of October 11, 1882 for a lecture, Decorative Arts, presented at the Market Hall. The lecture was advertised in the the local newspapers, including the Daily Patriot:

Newspapers also made editorial mention of the lecture; on October 10, 1882, this item appeared in the same Daily Patriot:
Oscar Wilde is after all coming to the Island. He is to lecture in the Market Hall to-morrow evening. There will no doubt be a great rush to hear and see the famous aesthete, and while his love of the beautiful and sense of the fitness of things will no doubt sustain many shocks in our town we think that he cannot but be pleased with the loveliness of our Island province.
The Patriot followed up the next day with a quick reminder – actually, two – in the October 11, 1882 “Local and Other Items” column, a column that also included notice of the Teacher’s Convention, Exhibition Day and disagreeable weather:

The following day, October 12, 1882, the Daily Patriot contained a report of the lecture, headed “Oscar Wilde’s Lecture,” which reads as follows:
This well advertised man lectured in the Market Hall of this city last night. Mr. Wilde affects singularity, but there did not appear to us anything very remarkable in either his dress, his personal appearance, or his lecture – certainly not enough to warrant one-tenth part of what has been said and written about him. His dress, neither in color or cut, was, as far as we could see, very different from that of ordinary young Englishmen. He evidently had on his ordinary travelling suit. It was grey, relieved by a bit of color at the neck and breast. He wore knee breeches which were decidedely baggy at the knees, and his blue stockings, although they displayed a well-shaped calf, were not at all different from the stockings we have seen on other young fellows. Mr. Wilde wears his hair long, but we saw not long ago a Quebec pilot with a longer and a handsomer head of hair, and his head, either for shape or covering, would not compare too favorably with that of a western Indian whom it was our privilege to see some time ago. Mr. Wilde is too effeminate in his appearance to be a handsome man, and he is too masculine to pass for a good looking woman.
His style of speaking is consistent with his personal appearance. It is odd, without being either very strong or very beautiful. His attitudes are not exceedingly graceful, particularly when he places his hands on his hip, as he is apt to do, and makes a handle to himself of his arm. He does not gesticulate much, but if he raised his other arm high enough he would not in that attitude make a bad model for an aesthetic coffee pot. Affectation is Oscar Wildes strong point – affectation in dress, affectation in manner and affectation in speech. His want of naturalness is we think, what affects many people so disagreeably when they hear him for the first time and causes them to rage against him so violently.
His lecture is a good lecture enough. It is a discourse teaching that honesty, sincerity, and fidelity to nature are the foundation of beauty in art, and that men would be wiser, better and happier than they are if they were surrounded from their childhood by things that are really beautiful. Mr. Wilde attributes a moral influence to the design and the tints of a wall paper, to the pattern and color of a carpet, to the form of a water jug, to the shape and ornamentation of a stove, and so on, of all common things by which we are surrounded. He believes because of the moral as well as the intellectual influence of beauty, they should all be as beautiful as the most cultivated taste can make them. We are not sure that he is not, to a certain extent, right. A thing of beauty is a joy forever for human beings of all ages, and all races, but men differ widely in their ideas of what is beautiful. Mr. Wilde teaches that nature in all her aspects is beautiful, and if his theory of the moral influences of beauty is true, those who live most of their time under nature’s covering and surrounded by nature’s works – the American Indian and the Afcrian negro for example – will be the most refined as well as the best of the children of men. Is this so? Mr. Wilde’s gospel of beauty like all other human gospels needs, we fear, a good deal of qualifying. One part of Mr. Wilde’s lecture deserves the serious attention of all parents and every one who has to do with the education of children, and that is, where he insists upon the necessity of teaching boys and girls of all ranks in life to use their hands. The number of men and women who are brought up in these days without learning to use their hands in any useful way is absolutely appalling. When reverses come upon these handless people, and when they are placed in a postiion – as nearly every man is at some period of his life – where his intellectual acquirements are of little use to him and where his very existence depends upon a more or less skillful use of his hands, he is the most helpless, and the most pitiable of creatures. No boy or girl is any the worse for learning some handicraft. Acquiring it will not retard, but assist his merely intellectual education. He will always be better of having learned it and it may be of the very greatest use to him. Mr. Wilde’s lecture teaches what many people to it hard to understand – the use of beauty.
Oscar Wilde was 27 years old at the time of his visit – he turned 28 the following week. The next evening he was in Moncton, then Saint John to finish, and on to New York City where he spent 10 weeks “flitting restlessly from hotel to hotel” and had all manner of adventures. On December 27, 1882 he sailed for London, a departure the New York Tribune reported like this:
Oscar Wilde has abandonded us without a line of farewell, slipped away without giving us a last goodly glance, left without a wave of his chiseled hand or a friendly nod of his classic head. This is the end of the aesthetic movement.
Oscar Wilde never returned to Charlottetown.
Credit to Declaring His Genius: Oscar Wilde in North America and to Catherine Hennessey, who first blogged about Wilde’s visit to Charlottetown 13 years ago.
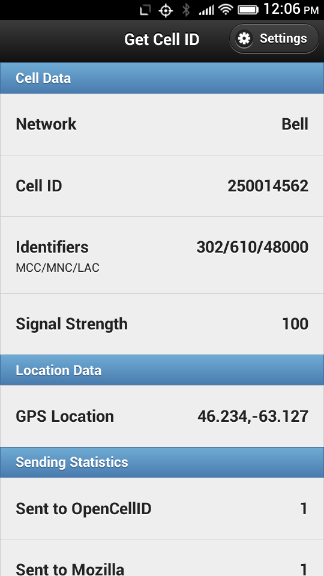 Last week Mozilla unveiled Mozilla Location Services, which it describes as “a new experimental pilot project to provide geo-location lookups based on publicly observable cell tower and wifi access point information.”
Last week Mozilla unveiled Mozilla Location Services, which it describes as “a new experimental pilot project to provide geo-location lookups based on publicly observable cell tower and wifi access point information.”
In other words, it’s a system to allow mobile devices send information about (a) where they are, from GPS and (b) what cell tower they’re connected to and/or what wifi networks they can see, to Mozilla in a way such that mobile devices can then, without GPS, extrapolate their location from this same information.
Similar more-closed systems are already run by Google, Apple and others: this is why, for example, your wifi-only iPad can approximate its location. There are also several other more-open systems in place that do the same thing, OpenCellID.org perhaps the most capable.
An odd irony to Mozilla’s project is that Mozilla’s Firefox OS mobile operating system doesn’t currently allow apps in the Firefox Marketplace that are capable of accessing the device’s cell tower information; such apps must be “certified” and this is something that only “core” apps support.
So Mozilla has released a mobile service that devices running its own mobile devices are essentially incapable of contributing to.
Fortunately it’s only essentially incapable, as it’s possible to install apps to Firefox OS devices directly, through the Firefox OS Simulator. Which is how I’ve been able to modify my app, Get Cell ID, to support reporting to Mozilla Location Services.
I built this app some months ago to send data to OpenCellID.org, and I’ve extended it to support sending both to Mozilla Location Services and to a custom URL of your choosing.
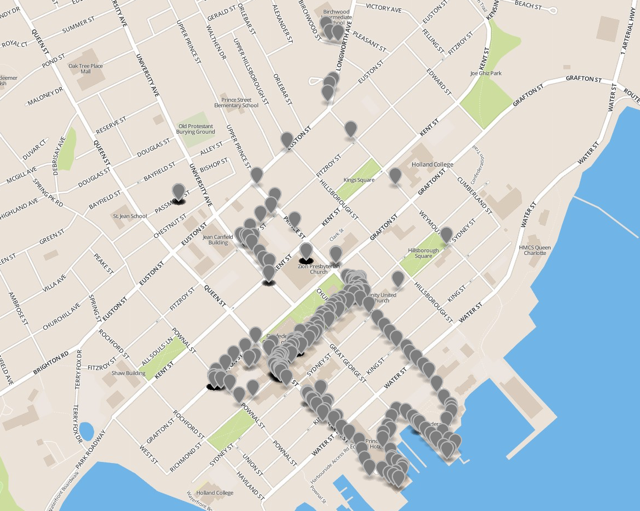
Because the app now supports reporting to a URL of your choice, it’s possible not only to log the data to third-party services, but to use the app as a sort of “digital bread crumbs” tool; for example, here’s a map showing my own reported locations over the past few days here in Charlottetown:
I made a hacky little AppleScript to sort through the birthdates for the 90 of my 784 contacts (11%) where I have record of something. Of those 90 contacts:
- 41 are older than me (45%)
- 4 are the same age as me (5%)
- 44 are younger than me (49%)
So I think that means I am neither old nor young but rather just right.
Back in July I wrote about the need to improve the “courtesy emails” sent to patrons in advance of items being due. At the time I proposed a new graphical format for the notices; at present, though, the Evergreen system Robertson Library uses doesn’t support MIME email, so these emails must be plain ASCII for the moment.
What I’m proposing instead, is to replace the existing notice template that results in notices that look like this:
Subject: UPEI Robertson Library Courtesy Notice
Dear Peter Rukavina,
Our records indicate these items are due in 3 days:
Please return or renew this material before fines accumulate.
Note that laptops and other reserve items cannot be renewed.
You may renew your material in one of 3 ways:
- online with your "My Account" page
(https://islandpines.roblib.upei.ca/opac/en-CA/skin/roblib/xml/myopac.xml?ol=4&l=4&d=2)
- by phoning 902-566-0583
- by replying to this email circdesk@upei.ca
Thank You.
How we decide, by Lehrer, Jonah.
Call Number: BF448.L45 2010
Due Date: 2013-06-24
Barcode: 37348007190119
With a template that results in notices that look like this:
Subject: UPEI Library books due in 3 days You have UPEI Library books due in 3 days: +- Due Saturday, June 24 + "How we decide" You may renew these: 1. Online at http://library.upei.ca/renew 2. By telephone at (902 )566-0583. 3. By email to circdesk@upei.ca Laptops and reserve items cannot be renewed.
Here’s what’s changed:
- Modifed the subject line to describe actual contents of email (“courtesy notice” doesn’t mean anything to real people).
- Removed references to “Robertson Library” and replaced with “UPEI Library”, which is more widely understood.
- Removed salutation (“Dear Firstname Lastname”) - it serves no purpose, as the email is already addressed to the recipient in the header.
- Put the due books up front rather than buried at the bottom.
- Removed the useless item-related metadata (call number, barcode, author) and just display the title.
- Changed the date format from the hard-to-parse “2013-06-24” to a human-readable “Saturday, June 24”.
- Replaced the complicated-looking URL for online renewal with a shortened URL (that would redirect to the Evergreen page).
- Remove “Thank You”.
I welcome comments on the proposed new format.
I have known about the Nordic “Live Action Role Playing” (LARP) movement since my friend Olle, one of its practictioners, first told me about it when we met all those years ago.
For someone like me with no connection to LARP, it has always been a hard practice to understand, taking place in an unfamiliar nexus of theatre, improvisation, make-believe and board game playing. Over the years I’ve been able to eke out a basic understanding from Olle, and from his partner Luisa, who’s also an adherent, but I’ve always felt it was an incomplete one: there are only so many detailed questions you can ask your friends about something that’s so familiar to them.
And so when the opportunity to attend some sessions at Alibis for Interaction that, together, formed a sort of “LARP 101,” I jumped at the chance.
The first was Why We Play – Larp As A Tool For Learning by LARP evangelist Miriam Lundqvist; her company, LajvVerkstaden – The Larp Workshop – uses LARP as an educational tool, and she gave a good summary of how, in her words, “narrative games on all platforms are increasingly also designed on serious topics.”
She was followed by Jaakko Stenros, who delivered on the dauntingly-title talk Living The Story, Free to Choose – Participant Agency in Co-Created Worlds. He provided a detailed look into the world of LARP, both in theory and practice, and in the transcript of his talk you can tease out a lot about what’s essential to LARPing in the Nordic countries, including this characterization of what it is like to LARP:
Let us consider the form of larp. Larp is embodied participatory drama. As a participant, you are experiencing the events as a character, but also shape the drama as it unfolds as a player. You have a sort of dual consciousness as you consider the playing both as real – within the fiction – and as not real, as playing.
You are both a player and a character, which creates interesting frictions since you inhabit the same body.
There is no external audience in larps. However, there is an audience, the audience of the participators. The performer and the spectator are also brought together in one body. In larp, we talk about the first person audience; in order to see and witness these works, you must participate.
I now feel well-grounded in the basics of what LARP is, how it is practiced, and for what ends.
I remain, however, completely mystified by it.
Not because I don’t understand what it’s about, nor because I don’t see its value. Indeed, it seems like something amazing.
But I’m someone who, at least as I conceive of myself, is incapable of taking on a persona: I feel skittish giving an assumed name at the Starbucks counter, so seeing myself as a butter forger seems beyond my capabilities.
I remain curious, however, and so perhaps given the right situation I will through caution to the wind and adopt the persona of someone who can imagine himself playing a LARP. At least now I know more about what I’d be getting myself into.
Yesterday was a long travel day home to Charlottetown: I woke up at 5:00 a.m. local time in my Malmö apartment and went to sleep in my Charlottetown bed at midnight, almost a 24 hours later.
One of the legs in that journey was a British Airways flight, № 811, from Copenhagen to London, a flight scheduled to fly as a ferocious wind storm was making its way through Europe. So I expected the worst.
I first noticed that something was untoward when I tried to do the machine self-checkin at the Copenhagen Airport: I was directed to the counter to check in manually, which is never a good sign.
The clerk at the (mercifully short) line told me that the flight might be delayed, but that I should proceed to the gate for the scheduled 8:05 a.m. departure time. She was friendly and efficient, and there was a printed “hey, this might be a rough travel day” letter on the counter in front of her to reinforce what she told me.
A quick pass through security (I believe I may have been misidentified as priority passenger “Herr Bergmann,” but I wasn’t going to look a gift horse in the mouth) and I was enjoying a coffee and sandwich at Joe & The Juice ten minutes later (it’s a distinctly un-airport-feeling kind of place, and thus an excellent place to fool yourself into thinking you’re just hanging out).
During this time the British Airways mobile app was displaying a rather odd situation, where the plane was departing on time, but arriving more than 90 minutes late:
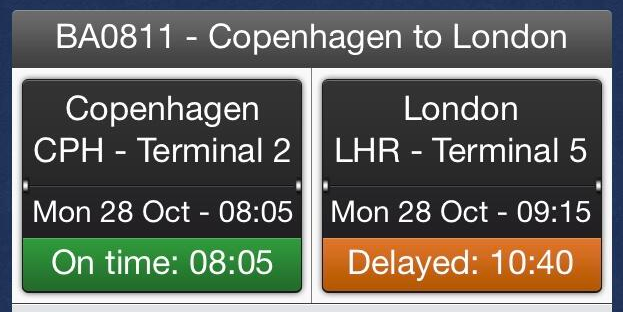
The reason for this became apparent when I got to the gate: Heathrow airport had moved the flight’s “landing slot” to 10:40, but the airline’s plan was to board everyone as schedule with the hopes that we could get an earlier slot and be ready to go just in case.
And so that’s what happened: acting as though everything was perfectly normally, the flight boarded for an 8:05 a.m. departure.
And then, once we were all aboard, the captain, a pleasant chap with a dry wit and hearty laugh, came out into the cabin to break it all down for us: if everyone had been left to mill about the terminal and an earlier landing slot came up, they wouldn’t be able to pounce on it, so their plan was to load us all up, do the safety demo, and then pull back from the gate, fire up the tea boiler, and tuck in for a wait.
As it happened, as soon as we pulled away from the gate and taxied out to the area where tea boiling is permitted (by virtue of being allowed to run the auxiliary power unit, which isn’t allowed at the gate), a landing slot did come available at Heathrow, and we took off shortly thereafter.
Our actual departure, thus, was 8:42 a.m. and we landed at 9:50 a.m., only 35 minutes late.
Communication was clear; expectations were communicated (“we might be really late, but we’re going to try to see what we can do”); and so when we arrived late, it seemed like a gift rather than a customer service issue.
Bravo, British Airways, for doing what so many other airlines cannot seem to do. I will fly with you again.
An eagle-eyed reader of the blog spotted this notice in the 1970 Prince Edward Island Official Road Map and Tourist Guide:

The Alibis for Interaction conference is over, my final goodbyes to European friends have been said, and I am packing up the Malmö operation for return to Charlottetown tomorrow (it’s a long day of travel that starts at 1:00 a.m. Atlantic and ends at 11:00 p.m. Atlantic; with a stopover at London Heathrow where, as I type, “the worst weather since 1987” is happening, so, who knows).
I came to Sweden for Alibis for Interaction on the strength of my good friend Luisa’s role in helping to organize it and because encapsulated in the name was a notion that lies at the heart of my own confused relationship with the universe: bridging social gulfs. The simple idea of the “alibi for interaction” – an excuse, an inspiration, a cue, a setting, a framework or, as I came to learn, a “magic circle” – seemed like a powerful way of expressing this.
And so, in truth, I knew I was coming as soon as Luisa told me the name.

It’s hard to summarize a two-day immersive experience like Alibis: this wasn’t a “I learned some new tricks for optimizing JavaScript callbacks” conference, this was a “can you reverse engineer mingling for me, please?” conference. That the conference involved some siginficant personal transformation for me makes it doubly difficult to describe, both because it seems sort of unbelievable and absurd as I write about it and because, well, personal transformation is difficult to describe.
Suffice to say, perhaps, that when I asked that question – “I don’t understand mingling, can you explain it to me?” – to someone chosen at random, someone who turned out, by incredibly lucky happenstance, to be a kind-hearted writer with a deep awareness of the mechanics of mingling, her own struggles with it, and Olympic level social skills to boot, I got an answer. A helpful, thoughtful, practical answer. Or, really, set of answers and techniques and tips. Like “when you’re in a room full of people you don’t know, smile; make eye contact with people; if they make eye contact with you and smile back, that’s a good cue to go and talk to them.”
It wasn’t as much the advice itself that was the transformative aspect (although it was truly helpful): it was the context, the relationship to the formal “how to design positive experiences for groups” talk from the podium, and to the exemplar exercises in everything from LARPing to “deep dating” that, taken together, put forward the idea – perhaps obvious to you, but novel to me – that social dynamics are something over which you can exercise control.
So I learned two important things at Alibis.
First, despite my insistent protests to the contrary, I am not shy. That was a surprise, and the revelation came simply by suddenly realizing, unprompted, that the bulk of my shyness was a result of self-identifying as shy. I may not be an extrovert (although even that’s up for debate), but being an introvert doesn’t mean that I’m terrified of social situations, or at least doesn’t have to mean this. In short, I’m calling bullshit on myself on this one.
Second, and as important, is that being skilled at making connections with other people, something I had heretofore regarded as a God-given miracle talent of everyone else but me, is, in fact, a learnable skill.
If there was an aggregate message of Alibis for Interaction it was “we can design positive social experiences that can change the world.” In my case the spin-off benefit of having this notion coursing through the air was the sudden recognition that I have agency in the social sphere: I can design positive social experiences that can change the world. And me.
I can’t overstate how profound, quantum and useful this revelation was: upon realizing it, I proceded through the rest of the conference as a substantially changed actor. My interactions with others seemed free and easy and unpanicked in a way that was, dare I say, fun. I learned things. I shared experiences, related stories, listened, chatted.
The seminal experience of the conference, the one where I got to take my newly renovated brain out for a ride, came on the evening of the first day when the conference relocated up the Skåne coast to a restaurant for a multi-course vegetarian meal. Seating was at random and I happened to end up at a table with three Swedish women in their twenties, interns from the local event-planning program who were helping to run the conference,
Rather than an awkward stumbly evening of terrified shyness this ended up being a delightful evening of conversation about myriad topics with a diverse and fascinating trio with whom I might have no other opportunity to interact in such a way. I learned about their lives, their plans, their struggles, and they learned something of me.
And this worked – and this seems crazy as I write it, but it’s true – simply because I sat down thinking “I can help make this work out” rather than “oh no, I have to get out of here.”
I can help make this work out.
That’s a powerful notion. And perhaps it’s a simpler way of summarizing what Alibis for Interaction was all about.
About This Blog
 I am Peter Rukavina and this is my blog. I am a writer, letterpress printer, and a curious person.
I am Peter Rukavina and this is my blog. I am a writer, letterpress printer, and a curious person.
To learn more about me, read my /now, look at my bio, listen to audio I’ve posted, read presentations and speeches I’ve written, or get in touch (peter@rukavina.net is the quickest way).
I have been writing here since May 1999: you can explore the 25+ years of blog posts in the archive.
You can subscribe to an RSS feed of posts, an RSS feed of comments, or a podcast RSS feed that just contains audio posts. You can also receive a daily digests of posts by email.