


Without any fanfare, the Province of Prince Edward Island launched a new website today, PrinceEdwardIsland.ca, and the most exciting aspect of the new site is that it telegraphs the Province’s plans for open data.
Under Online Services > Open Data, you’ll find a list of data sets.
Like this one, with data about the popularity of the various conservation license plates in recent years. There’s a link to a CSV file at the bottom of that page; open it in a spreadsheet and it looks like this:
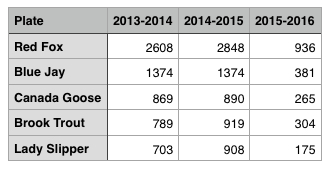
It’s nice, clean, CSV, not just “File > Save As > Excel” data, and that makes it easy to quickly create charts like this, graphically illustrating the popularity of the plates for last year:
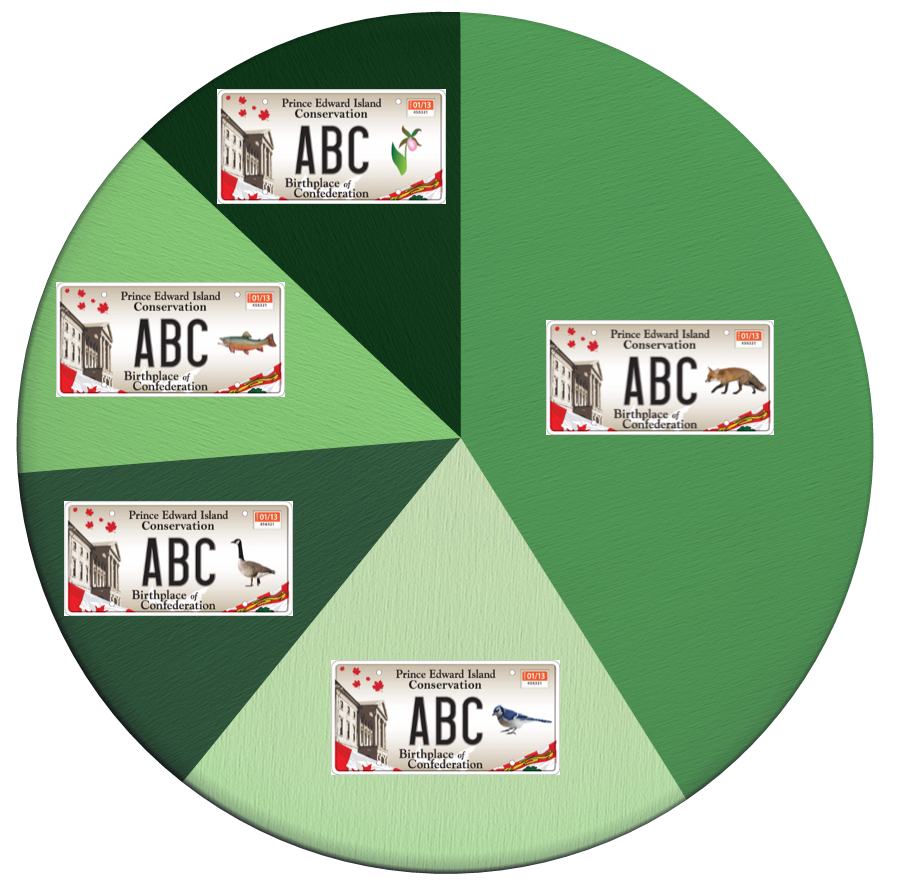
(I thought I was in the elite squad of Red Fox plate-owners; turns out I was just following the herd).
You won’t find all the data the province holds online – this is the first toe in the water – but it’s certainly a very good start: there’s everything from data about doctors to data about oysters. And the province’s license, principles and standards, modeled after the Government of Canada’s, appear sound. It’s hard not to love an effort that has non-discrimination as one of its core principles:
Non-discriminatory access to data should enable any person to access the data at any time without having to identify themself or provide any justification for doing so.
Wearing my Hacker in Residence hat, I spent much of last year talking to public servants about open data; although greater forces than I have conjured up the political will to make this happen, I’m happy to have a played a small nudging role in this effort. I’m excited to see what comes next, not only in terms of data sets, but in the gradual migration to an attitude in the public service where institutional street cred is derived from being more open, more often.
Back in the early 1990s, shortly after moving to Prince Edward Island, [[Catherine]] and I had our first occasion to take the Borden ferry to the mainland, as part of a trip to Halifax to visit friends.
Following the crowd from the vehicle decks up to the cafeteria, we spotted Roger Younker, then the host of CBC Compass, the supper-hour television news cast. We were (or perhaps, more accurately, I was) star struck: a God walked among us. And he was enjoying two eggs over easy.
As we became acclimated to Island life in subsequent years I came to realize that spotting Roger Younker on the ferry wasn’t as much of a deal as it initially seemed, but that impression of the cafeteria as the agora in which Islanders of all walks of life could break bread together before heading out into the cruel indignities of the mainland remained with me.
And when the ferry was replaced by the Confederation Bridge it was that absence I missed the most.
Last week I had occasion to chat with a colleague at The Old Farmer’s Almanac about his family’s vacation to the Maritimes last summer; he pulled out his mobile phone and showed me some of the photos he’d taken at Hopewell Rocks in New Brunswick, site of the highest tides in the world. I realized that, in the 23 years we’ve lived on the Island, we’ve never been across to see the Bay of Fundy, and upon returning home on Saturday this fact loomed large; I could have suggested a family trip later in the season, but I feared that, like the last 23 years, it would be pushed to the bottom of the pile and remain a dream unrealized.
And so after breakfast yesterday I suggested we take an impromptu trip to Hopewell Rocks. Right away.
[[Catherine]] and [[Oliver]] are nothing if not game for the impromptu trip, and so 15 minutes later we were on the road.
I suspect that I’m not unique in feeling, when driving toward the Bridge, that as soon as you reach the greater Crapaud-Tryon area you have escaped something of the gravitational pull of Charlottetown and attained escape velocity; a new sense of calm comes over the car at this point, as a collective sigh of relief is breathed.
Historically it was inside this breath – sometimes punctuated by an extended wait in the ferry line – that one would have breakfast with Roger Younker; on Sunday we replaced this with a visit to Scapes, the improbably-located restaurant on the fringe of Gateway Village, the simulated community at the lip of the bridge.
While the balance of Gateway Village is a simulacrum, Scapes is a very much real, delightful place to grab a bite to eat, owned and operated by Sarah Bennetto O’Brien, a passionate chef who cares deeply about local, healthy food.
We enjoyed a lunch of scratch-made fish cakes (for Catherine and me) and a BLT (for Oliver), served by friendly staff in a tiny pleasant room.
Sitting on a stool at the front of Scapes waiting for my fish cakes, I realized that it’s the new way to prepare for embarkation: the new culinary precipice from which we can gather ourselves to confront life onshore.

If Sarah could arrange for Roger Younker to drop in occasionaly, the scene would be perfect.
The more passionate among fans of The Old Farmer’s Almanac can sometimes be seen posing in front of the Almanac.com Webcam to create a souvenir of their drive through the Almanac’s home here in Dublin, New Hampshire. This morning I happened to be the first person in at the office – a victim of my body clock still being on Atlantic Daylight Time – and so I had my pick of parking spots and was able to park right in the middle of the camera’s field of view.
And so, here’s me, with my rental Toyota Yaris, at 6:59 a.m. this morning:

More than 12 hours later, after supper with colleagues, I popped back into the office to attend to some fiddly bits of advertising code, and so the camera captured me, again in an emptied parking lot, just pulling in:

I had the lucky chance to be able to share coffee with an insightful group of people last week, most of them dietitians, to talk about school food.
At one point in our conversation I admitted that I didn’t know what protein is.
Other than having a vague sense that I need protein to survive, and that I can get it by eating things like meat – he takes a moment to Google “sources of protein” – eggs, tofu, nuts, and beans, I had no idea why I might need protein to survive. Nor what eating more, or less, or better, or worse sources of protein would do to me.
Fortunately my dietitian friends greeted my admission of ignorance kindly; indeed one of them suggested that perhaps knowing about the ins and outs of protein might be a lot less important than simply understanding what eating “whole foods” is about.
But, regardless of their kindnesses, I decided I needed to learn about protein.
Fortunately I had, on my recent trip to London, come across the book Gut: The Inside Story of Our Body’s Most Underrated Organ in the London Review Book Shop and purchased a copy. While the book isn’t about protein specifically – it has far more to say about the mechanics of poop – it does helpfully provide a well-worded short course on the fundamentals of food. And it has this to say about protein:
Having examined carbohydrates and fats, there is just one more nutritional building block to consider. It is probably the least familiar: amino acids. It seems strange to imagine, but both tofu, with its neutral-to-nutty taste, and salty, savory meat are made up of lots of tiny acids. As with carbohydrates, these tiny building blocks are linked in chains. This is what gives them their different taste and a different name: proteins.
Digestive enzymes break down these chains in the small intestine and then the gut wall nabs the valuable components. There are twenty of these amino acids and an infinite variety of ways they can be linked to form proteins. We humans use them to build many substances, not the least of which is our DNA, the genetic material contained in every new cell we produce every day. The same is true of other living things, both plants and animals. That explains why everything that nature produces that we can eat contains proteins.
That’s exactly the concise explanation of what protein is that I needed: it allowed me to take the disconnected bits of protein trivia I’ve been floating through all my life and to start to bind them together.
It also makes eating protein sound pretty important to success in life.
This is only one of the wonderful things I learned from the book Gut. Beyond the aforementioned poop mechanics, I learned about fats and carbohydrates, about the immune system, about saliva, about what the appendix does. And I’m only halfway through the book. It’s entertainingly written, well illustrated, and, as with the treatise on protein, provides just the right amount of information to allow one to start making sense of how food and body work together to support life.
As the story of protein continues in the book, it gets even more interesting:
Plants construct different proteins than animals, and they often use so little of a given amino acid that the proteins they produce as known as incomplete. When our body tries to use these to make the amino acids it needs, it can continue to build the chain only until one of the amino acids runs out. Half-finished proteins are then simply broken down again, and we excrete the tiny acids in our urine or recycle them in our body.
After reading that paragraph I went from simple connecting-the-dots to a sudden and profound shift in my world view:
When we eat plants and animals we are simply taking the stuff they used to make themselves, and using it to make ourselves.
That may be self-evident to you, but this revelation has just completely rocked my world.
I’d simply never thought of plants and animals this way, and never connected the notions of eating, plants & animals, and protein all together in a systematic way.
Amino acid swapping. That’s what it’s all about. That is amazing.
I’m so glad I admitted I didn’t know what protein was, and that I set out to correct that.
I landed in Boston 3 hours ago and it’s been pouring rain since.
Things died down a little as I stopped for supper at Mi Jalisco in Milford, but as I emerge, 30 minutes later, it’s raining as hard as I’ve ever seen it. Here’s a taste.

We visited the new Princess Auto store in Charlottetown for the first time tonight (it opened yesterday).
We had little idea what to expect. And even after visiting the store I can’t tell you exactly what business they’re in.
But I did buy a stethoscope for $13.
Why?
Because at the vet on Tuesday when Dr. Jameson was checking Ethan’s heart I distinctly remember thinking “it would be so great if civilians were allowed to have stethoscopes.”
And apparently we are.
It turns out that a stethoscope is essentially a tube with a tiny snare drum at the end. I had no idea (I’m not sure what I thought a stethoscope was, but it wasn’t that).

For the benefit of future residents of 100 Prince Street, reading this on your holoreaders, here’s a photo of the replacement tree that was planted the City of Charlottetown on Monday, May 30, 2016 in front of the house.
I hope you are enjoying its shade.

About This Blog
 I am Peter Rukavina and this is my blog. I am a writer, letterpress printer, and a curious person.
I am Peter Rukavina and this is my blog. I am a writer, letterpress printer, and a curious person.
To learn more about me, read my /now, look at my bio, listen to audio I’ve posted, read presentations and speeches I’ve written, or get in touch (peter@rukavina.net is the quickest way).
I have been writing here since May 1999: you can explore the 25+ years of blog posts in the archive.
You can subscribe to an RSS feed of posts, an RSS feed of comments, or a podcast RSS feed that just contains audio posts. You can also receive a daily digests of posts by email.