
Many, many years ago when we were both wearing different hats, Bryson Guptill and I went on a “prospecting” trip to Toronto on behalf of the Government of Prince Edward Island. I was along as a sort of “technical advisor” and Bryson was leading the charge. It was a bizarre trip the likes of which I was never asked to go on again. And as far as I know it bore no fruit for the province.
But it did introduce me to Bryson, and we’ve maintained an acquaintance in the years since.
These days Bryson’s passion is hiking, and the most recent manifestation of this was a 34-day walk of the Camino Francés from St. Jean Pied de Port, France to Santiago de Compostela, Spain. He turned the tale of the walk into a book, Camino Francés: A Practical Guide to Walking the Pilgrim’s Path from France to Spain, and asked for my help in creating a companion web-map for the book.
Bryson’s been an avid OpenStreetMap contributor for the last 8 years, and so he had the forethought to drop GPS breadcrumbs as he was walking, and the technical savvy to get these into a Google Map on his return. He wanted my help to create a purpose-built map, using OpenStreetMap rather than Google Maps, and so that’s what I built.
The first thing Bryson needed to do was to create a simplified route: he’d been dropping breadcrumbs with enough frequency that the resulting GIS data was much too detailed for our purposes. So he retraced the route by hand, and created a much more reasonably-sized layer.
I exported this from Google Maps into a KML file, and then transformed the KML into a GeoJSON file using geojson.io. I split the route–a line–from the overnight stops along the route–points–into two separate GeoJSON files, cleaned up the order of the waypoints, and added some metadata to them (the name of the lodging, the distance traveled that day, etc.).
With the data in-hand (camino-frances-route.geojson and camino-frances-waypoints.geojson) I created a web app, using the excellent Leaflet JavaScript library, the Awesome Number Markers plugin, along with jQuery and jQuery Mobile. For the base map and hill-shading layers, I used tiles from the OpenStreetMap-derived Hike & Bike Map.
You can see the result at caminofrances.info and you can learn more about Bryson’s walk at the Charlottetown launch of the book, Tuesday, February 21, 2017 at 7:00 p.m. at Confederation Centre Public Library. I’ll be there too if you’d like to chat about the map.
I noticed last night while stacking used egg carton, that they are labelled “1/2 DOZ.” on either end, which gives one tacit permission to rip them in half and purchase only 6. I’d seen people do this before, but always assumed it was a risky renegade move.
Apparently it’s expected.

The best time to do the weekly grocery shopping, in my experience, is on Saturday night: our local Sobeys is all-but-deserted, but still well-stocked, there’s The Eric MacEwen Show to listen to on the radio on the drive home, and an interesting collection of Charlottetown luminaries have also figured out the Saturday-night-shop-secret, and so there are always people to keep me entertained (Fred Hyndman shops: who knew!).
Because Sobeys is deserted, I usually don’t have a problem finding a free cashier, and while there are some experienced and hyper-efficient staff working Saturday nights, it seems to attract the silent rather than the voluble, so our conversations at the cash are seldom any more than “Do you have an Air Miles card?”
Last night, though, a young man named Jonathan was at the cash. When he asked me “so, what are you up to tonight?”, I gave him a dismissive small-talk answer, assuming that was what he expected.
Except he didn’t: somehow we ended up chatting about Netflix while he was ringing me in, and what we were watching on Netflix. I told him I’d just finished Black Mirror (which he misheard as Black Mayor, and claimed no knowledge of), and he told me about the new documentary series Abstract.
And so this morning over waffles that’s what I watched.
And it’s a great series: an imaginative look at the imagination and the art of design and creation. I’m so glad he recommended it to me.
Jonathan, I think, is what’s standing between us and robotic-overlord cashiers: a genuinely social and curious person who humanizes a job that so often seems anything but.
Watch for him on Saturday nights when you’re doing your shop. And say hi to Fred for me.
After 45 days of making up crossword puzzles for Oliver as he’s going to bed, tonight we tried our hand at the New York Times mini-crossword together.
Oliver solved 7 of the 10 clues on his own, including MONET, which he came to well before I did.
(My favorite crossword moment so far was when Oliver filled in ANTEATER when my design called for ANTELOPE; both fit the space and the clue).

The CBC Storm Centre is the de facto place to look online for what’s delayed, closed and cancelled during severe weather on Prince Edward Island.
I was curious to know what’s under the hood of the web app, as it appears to be loading data from a remote source when you open the page, leaving open the notion that there’s some sort of open data lurking in the shadows that one might leverage for other purposes.
Opening the Firefox Developer Tools while the Storm Centre is loading, the first thing you notice is an AJAX request for a JSON resource that describes a Google Spreadsheet:

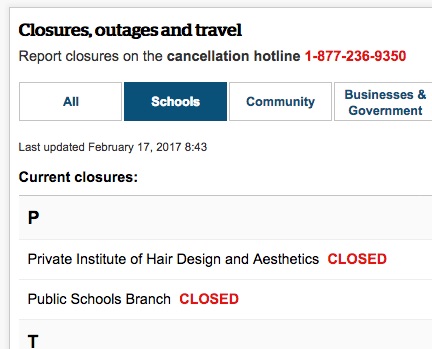
Looking at the contents of that file, I find a link to this public Google Spreadsheet, which contains all of the data related to closures for the Storm Centre. For example, there’s a row showing “Private Institute of Hair Design and Aesthetics” is closed:

And, sure enough, that’s what’s rendered into the Storm Centre:
Also in that original JSON resource there’s a link to an XML version of the same data, wherein the same data can be found, with one entry element per closure:
<entry>
<id>https://spreadsheets.google.com/feeds/list/16JACsgpXZkzpQkyzDkzzZxehhtvnnfjbyGY7CDyeq3o/od6/public/basic/dcgjs</id>
<updated>2017-02-17T17:05:50.230Z</updated>
<category scheme="http://schemas.google.com/spreadsheets/2006" term="http://schemas.google.com/spreadsheets/2006#list"/>
<title type="text">Schools</title>
<content type="text">closurestatus: Closed, name: Private Institute of Hair Design and Aesthetics</content>
<link href="https://spreadsheets.google.com/feeds/list/16JACsgpXZkzpQkyzDkzzZxehhtvnnfjbyGY7CDyeq3o/od6/public/basic/dcgjs" rel="self" type="application/atom+xml"/>
</entry>
That XML data has enough structure that it’s possible to use for alternate renderings of the storm closure data.
For example. here’s some hacky PHP that takes reads the XML and transforms it into a simple HTML file:
<?php
$closures = array();
$xml = simplexml_load_file('https://spreadsheets.google.com/feeds/list/16JACsgpXZkzpQkyzDkzzZxehhtvnnfjbyGY7CDyeq3o/od6/public/basic');
foreach($xml->entry as $key => $entry) {
if ((strpos($entry->content, "closurestatus: Closed") !== false) or
(strpos($entry->content, "closurestatus: Delay") !== false) or
(strpos($entry->content, "closurestatus: Cancelled") !== false)) {
$closures[] = parseEntry($entry->content);
}
}
array_multisort($closures);
$oldstatus = '';
foreach($closures as $key => $c) {
if ($c['status'] != $oldstatus) {
print "<h1>" . $c['status'] . "</h1>";
}
print "<h2>" . $c['name'] . "</h2>";
print "<p>" . $c['notes'] . "</p>";
$oldstatus = $c['status'];
}
function parseEntry($content) {
$elements = array();
preg_match('/closurestatus: (.*), name:/', $content, $matches);
$elements['status'] = $matches[1];
if (!preg_match('/name: (.*), closurenotes/', $content, $matches)) {
preg_match('/name: (.*)$/', $content, $matches);
}
$elements['name'] = $matches[1];
preg_match('/closurenotes: (.*)/', $content, $matches);
@$elements['notes'] = $matches[1];
$elements['notes'] = preg_replace("/, configlabel:.*$/", '', $elements['notes']);
$elements['notes'] = preg_replace("/, configvalue:.*$/", '', $elements['notes']);
$elements['name'] = preg_replace("/, configlabel:.*$/", '', $elements['name']);
$elements['name'] = preg_replace("/, configvalue:.*$/", '', $elements['name']);
$elements['notes'] = preg_replace("/, configinstructions:.*$/", '', $elements['notes']);
$elements['notes'] = preg_replace("/, configinstructions:.*$/", '', $elements['notes']);
return $elements;
}
The result looks like this, in part:
Cancelled
Chances Drop In Play in Stratford
Food Safety Course scheduled for Charlottetown today
Will be rescheduled at a later date
Closed
Chances Family Centre Programs (in schools)
French Language School Board
Delay
ACOA office in Ch’town
Delaying opening until 10:30, further announcement by 9
And so on. The reason the PHP is so hacky is because the “content” for each closure isn’t structured data within the XML; it’s just plain text:
<content type="text">closurestatus: Closed, name: Chances Family Centre Programs (in schools) </content>
And so some parsing is required.
But it’s a start.
Because y’all are no doubt asking yourselves “I wonder how they’re doing with the snow out there,” I am happy to report that the snow has stopped, the clearing has begun, and the Island awakens.
Our snow plough contractor, new this year and heretofore unremarkable, has risen to the challenge of the snowluge, and cleared our driveway to the pavement before I got up this morning.
There is no snow in the forecast.
Now, to do those things, live those unrealized dreams, that the snow prevented us from.

Winter, having realized that its “dump 30 cm of snow quickly and then be off” approach could be so readily dismissed, doubled down Thursday with a bold new “dump 2 cm of snow every hour, for 15 hours” strategy.
Citizens were caught unawares.
Point, winter.
In How to Navigate a Museum, in today’s New York Times, the best advice offered is this:
“A common mistake people make is to stay at a museum too long to try to see as much as possible, but this will only result in sensory overload and leave you overwhelmed.”
I put this into practice at the Victoria & Albert Museum when I visited last year: I spent 30 minutes in the architecture section, took a quick tour through the special exhibition on the theatre, dropped in at the bookstore, and was off. It was the perfect visit.

Friend Dave Atkinson sent a helpful note this morning:
I love getting your blog delivered to my inbox, but I note that something in the process makes photos not appear. Error messages on everything but the header.
I checked, and Dave was right: people subscribing to my posts by email have been seeing broken images in most situations. I set out to fix that (friends like Dave don’t come along every day).
The source of the problem was that, in the HTML of the body of my posts, I was inserting images like this:
/sites/ruk.ca/files/onetweet.jpg
In the normal course of affairs that’s fine: because the HTML is on a page already on ruk.ca, browsers are smart enough to know “that image onetweet.jpg, I’ll look for that on ruk.ca.”
But outside, in the harsh cruel world of email, no such logic applies, and so the images appear broken.
The solution is to change the images to reference the complete absolute URL, rather than just the relative path, like this:
https://ruk.ca/sites/ruk.ca/files/onetweet.jpg
Fortunately there’s a Drupal module called Pathlogic that does exactly that. And it was easy to set up. I just installed the module, enabled it, and then set it to use the “Full URL,” like this:

Finally, on the Text Format setting–Full HTML–that I use for my post body field, I checked the “Correct URLs with Pathlogic” setting:

And now the URLs, both here on the blog and in the RSS feed (which is what drives the email subscription system, via MailChimp) work in any context.
A heartfelt tip of the hat to the great Stuart McLean, who died today.
See Hacking Stuart McLean for the step by step.
About This Blog
 I am Peter Rukavina and this is my blog. I am a writer, letterpress printer, and a curious person.
I am Peter Rukavina and this is my blog. I am a writer, letterpress printer, and a curious person.
To learn more about me, read my /now, look at my bio, read presentations and speeches I’ve written, or get in touch (peter@rukavina.net is the quickest way). You can subscribe to an RSS feed of posts, an RSS feed of comments, or receive a daily digests of posts by email.