
The CBC Storm Centre is the de facto place to look online for what’s delayed, closed and cancelled during severe weather on Prince Edward Island.
I was curious to know what’s under the hood of the web app, as it appears to be loading data from a remote source when you open the page, leaving open the notion that there’s some sort of open data lurking in the shadows that one might leverage for other purposes.
Opening the Firefox Developer Tools while the Storm Centre is loading, the first thing you notice is an AJAX request for a JSON resource that describes a Google Spreadsheet:

Looking at the contents of that file, I find a link to this public Google Spreadsheet, which contains all of the data related to closures for the Storm Centre. For example, there’s a row showing “Private Institute of Hair Design and Aesthetics” is closed:

And, sure enough, that’s what’s rendered into the Storm Centre:
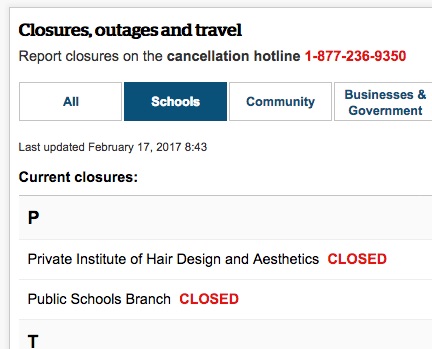
Also in that original JSON resource there’s a link to an XML version of the same data, wherein the same data can be found, with one entry element per closure:
<entry>
<id>https://spreadsheets.google.com/feeds/list/16JACsgpXZkzpQkyzDkzzZxehhtvnnfjbyGY7CDyeq3o/od6/public/basic/dcgjs</id>
<updated>2017-02-17T17:05:50.230Z</updated>
<category scheme="http://schemas.google.com/spreadsheets/2006" term="http://schemas.google.com/spreadsheets/2006#list"/>
<title type="text">Schools</title>
<content type="text">closurestatus: Closed, name: Private Institute of Hair Design and Aesthetics</content>
<link href="https://spreadsheets.google.com/feeds/list/16JACsgpXZkzpQkyzDkzzZxehhtvnnfjbyGY7CDyeq3o/od6/public/basic/dcgjs" rel="self" type="application/atom+xml"/>
</entry>
That XML data has enough structure that it’s possible to use for alternate renderings of the storm closure data.
For example. here’s some hacky PHP that takes reads the XML and transforms it into a simple HTML file:
<?php
$closures = array();
$xml = simplexml_load_file('https://spreadsheets.google.com/feeds/list/16JACsgpXZkzpQkyzDkzzZxehhtvnnfjbyGY7CDyeq3o/od6/public/basic');
foreach($xml->entry as $key => $entry) {
if ((strpos($entry->content, "closurestatus: Closed") !== false) or
(strpos($entry->content, "closurestatus: Delay") !== false) or
(strpos($entry->content, "closurestatus: Cancelled") !== false)) {
$closures[] = parseEntry($entry->content);
}
}
array_multisort($closures);
$oldstatus = '';
foreach($closures as $key => $c) {
if ($c['status'] != $oldstatus) {
print "<h1>" . $c['status'] . "</h1>";
}
print "<h2>" . $c['name'] . "</h2>";
print "<p>" . $c['notes'] . "</p>";
$oldstatus = $c['status'];
}
function parseEntry($content) {
$elements = array();
preg_match('/closurestatus: (.*), name:/', $content, $matches);
$elements['status'] = $matches[1];
if (!preg_match('/name: (.*), closurenotes/', $content, $matches)) {
preg_match('/name: (.*)$/', $content, $matches);
}
$elements['name'] = $matches[1];
preg_match('/closurenotes: (.*)/', $content, $matches);
@$elements['notes'] = $matches[1];
$elements['notes'] = preg_replace("/, configlabel:.*$/", '', $elements['notes']);
$elements['notes'] = preg_replace("/, configvalue:.*$/", '', $elements['notes']);
$elements['name'] = preg_replace("/, configlabel:.*$/", '', $elements['name']);
$elements['name'] = preg_replace("/, configvalue:.*$/", '', $elements['name']);
$elements['notes'] = preg_replace("/, configinstructions:.*$/", '', $elements['notes']);
$elements['notes'] = preg_replace("/, configinstructions:.*$/", '', $elements['notes']);
return $elements;
}
The result looks like this, in part:
Cancelled
Chances Drop In Play in Stratford
Food Safety Course scheduled for Charlottetown today
Will be rescheduled at a later date
Closed
Chances Family Centre Programs (in schools)
French Language School Board
Delay
ACOA office in Ch’town
Delaying opening until 10:30, further announcement by 9
And so on. The reason the PHP is so hacky is because the “content” for each closure isn’t structured data within the XML; it’s just plain text:
<content type="text">closurestatus: Closed, name: Chances Family Centre Programs (in schools) </content>
And so some parsing is required.
But it’s a start.
About This Blog
 I am Peter Rukavina and this is my blog. I am a writer, letterpress printer, and a curious person.
I am Peter Rukavina and this is my blog. I am a writer, letterpress printer, and a curious person.
To learn more about me, read my /now, look at my bio, listen to audio I’ve posted, read presentations and speeches I’ve written, see things I’ve favourited elsewhere, or get in touch (peter@rukavina.net is the quickest way).
I have been writing here since May 1999: you can explore the 25+ years of blog posts in the archive.
![]() You can subscribe to an RSS feed of posts, an RSS feed of comments, an RSS feed of favourites elsewhere, or a podcast RSS feed that just contains audio posts. You can also receive a daily digests of posts by email. I also publish an OPML blogroll.
You can subscribe to an RSS feed of posts, an RSS feed of comments, an RSS feed of favourites elsewhere, or a podcast RSS feed that just contains audio posts. You can also receive a daily digests of posts by email. I also publish an OPML blogroll.
Instagram • YouTube • Vimeo • ORCID • OpenStreetMap • Internet Archive • PEI.art • Drupal • Github.
Comments
Doesn't the open google sheet
Doesn't the open google sheet seem ripe for abuse? Or am I missing something?
It’s a read-only spreadsheet
It’s a read-only spreadsheet for the public.
Add new comment