
If you’re looking for a weekend activity in the outdoors, a winter walk in the woods at the Brookvale Demonstration Woodlot can’t be beat. The main trail is groomed and very walkable, and the trail is just the right length.
The woodlot is just northeast of Brookvale Ski Park, on the opposite side of the road. It’s about 35 minutes drive from either Charlottetown or Summerside.
The road into the parking lot isn’t plowed, so you need to park on Rte. 13 and walk in (groomed as well). Just walk up the entrance road until you get to the end of the trail—you’ll see the sign—and then walk the trail backwards to the trailhead. Then turn around and walk back out. At a leisurely pace it will take you about 40 minutes.

It’s not clear whether it’s the Crapaud Community Hall that’s welcoming new ideas, or the Village of Crapaud itself. Regardless, I appreciate the sentiment.
 ,
, 
Below are the formal remarks I made this evening on the floor of the Legislative Assembly regarding the Autism Secretariat Act.
There were friendly amendments to the bill adopted this evening during the debate that changed the name of the act to the Autism Coordination Act, and specified that a committee of deputy ministers be cast to oversee this coordination, a committee responsible to a designated member of Executive Council, and that would report at least annually to the Legislature.
The amended bill received unanimous consent after a thoughtful, collaborative debate. Barring any last minute changes, it will receive Third Reading and Royal Assent in the days to come.
Which is awesome.
MLA Sidney MacEwen deserves tremendous thanks for introducing the bill, working together to get it passed, and being open to amendments. All members who spoke to the bill deserve thanks for their open mindedness and for their comments in solidarity with people with autism.
It was a good night.
Thank you, honourable members, for the opportunity to contribute to this debate.
It is an honour to be able shed some light on the needs and aspirations of Islanders with autism and the challenges faced by their support networks, and to speak to the utility of establishing cabinet-level responsibility for autism.
I am here because I am the father of Oliver, a young adult on the autism spectrum. I am mindful that I see autism primarily through Oliver’s experience, and I am also mindful that I am not on the autism spectrum myself, so I cannot speak for people who are.
As a technologist, however, I understand a thing or two about how systems work, about the importance of leadership and coordination, and about how the bureaucracy works, and sometimes doesn’t work, and it’s those experiences, as well as my 18 years of parenting, that I bring to bear this evening.
A few days ago I consulted with Carolyn Bateman, chair of Stars for Life. “Have I got it right?”, I asked Carolyn about the remarks I bring to you now.
After some encouraging words, Carolyn wanted to make sure I accurately reflected the unique struggles of living with autism. Difficulties getting a diagnosis. Sleep deprivation. Meltdowns. Problems making friends. Issues with dating and relationships. Lack of safe, supported housing options. Problems getting and keeping a job. And her list went on.
Those are all real concerns.
I witness many of them every day, as do families across the Island.
But, with all due respect to Carolyn, that is not where I will focus my comments today.
I want to focus, at least to begin. on what we’re doing right.
I want to mention Dr. Peter Noonan, who was there in the delivery room when Oliver was born, who helped coax him to life, and who saw him every 6 months until he turned 18, who referred him to the IWK for an autism diagnosis, and, later, referred us all to the Strongest Families program to help us with anxiety.
The pre-school special needs team that helped Oliver with psychological supports and occupational therapy before he entered public school.
The staff at Holland College Child Development Centre, where Oliver went to daycare and kindergarten, who made sure, despite tight funding, that he had an educational assistant.
Teachers, resource staff, EAs and administrators at Prince Street, Birchwood and Colonel Gray schools who have done everything in their means to help Oliver learn and to participate in school life.
Of Taylor and Lauren and Drake and Johannes and Derrick and Lindsay, who, over the years, School Age Autism funding has allowed us to hire as community aids to support Oliver after school, in the community.
Of Barb, Oliver’s Disability Support caseworker, who’s helped us arrange for respite care and summer programming.
I mention these people, and these supports, because I want to make it clear that we have not been in this alone: this is a caring Island, an Island that understands that people on the spectrum need support, an Island that has lightened Oliver’s load and helped us be better parents to him.
We are thankful.
But here’s the thing: all of this is done almost entirely without coordination or integration.
As government’s Autism Action Group wrote in its 2009 report, “the department-based, or service-based silos are entrenched, and cannot be penetrated by the good will and intent of the Autism Action Group participants alone because each department or service applies very different approaches to ASD supports and services.”
And that is certainly our experience as Oliver’s parents.
I mentioned School Age Autism funding. This program, administered by the Department of Education, provides us with funding to hire community aids to work with Oliver after school and through the summer.
Oliver also receives Disability Support funding from the Department of Family and Human Services. That program overlaps with, but is not quite the same as School Age Autism funding, and has a completely separate staff, eligibility criteria, and forms to fill out.
We’ve received School Age Autism funding since Oliver’s diagnosis, but Disability Support funding only for the last couple of years.
Why?
Because we didn’t know it existed.
Somehow, from the autism diagnosis at the IWK, through years of public school, and regular appointments at the QEH, and all the while receiving School Age Autism funding, everyone assumed that we knew about the Disability Support program. But we didn’t.
No matter which provincial department the funding comes from, families who wish to hire someone to work with their child must register as employers with Canada Revenue Agency, and thus must make monthly payroll remittances, create T4s and records of employment.
Raising a child on the autism spectrum can be a complicated, exhausting endeavour; to juggle two funding programs, with two different parts of the bureaucracy, and to additionally deal with a federal department, is more than many families can take on, and so supports that could be incredibly helpful go unused.
We can do better than that.
The Department of Education has a “Guide to Early Years Autism Services” on its website, last updated in 2012, the introduction to which reads:
This guide will focus specifically on services for young children with autism provided through the Department of Education and Early Childhood Development. For more detailed information about programs and services available through other Departments, please see www.gov.pe.ca/departments.
Not only does that web page no longer exist, but the “there may be others in government who can help, good luck!” message is not helpful to the parent looking for support.
I think we can do better than that too.
In 2014, when we were working with the English Language School Board to make arrangements for Oliver’s Autism Assistance Dog Ethan to join him in school everyday, a school board official told us that “educational assistants are in schools to allow students to survive, not to thrive.”
While I admired their candour for admitting this, those words haven’t left me since I heard them.
We surely must be able to do better than that.
When I told Oliver that I was coming here tonight, I asked him if he would consider watching the live stream online and his quick reply was “of course I will, this is an historic milestone — like when women were recognized as persons.”
Oliver’s wise words allow me to highlight another important aspect of this bill: in laying out the objects and purposes of the bill, the emphasis not only on facilitating and coordinating services and programs for people with autism, but also “to heighten awareness of the needs and aspirations of people with autism.”
Aspirations.
That’s a word we don’t often hear when speaking about people with autism.
And yet people with autism, like everyone else, have dreams, plans for their lives, things they want to do, people they want to become. When Oliver spoke of tonight’s “historic milestone” he was, I believe, proud to live on an Island that was willing to say to people like him “you exist.”
But, as I began, I am not here, primarily, to make an emotional appeal to you.
I do not need to convince you that autism exists, that people with autism are important and valued Islanders, that parenting someone with autism can be both wrenchingly difficult and unimaginably wonderful, often on the same day.
I do not need to tell you that autism is unique and complex enough that it demands targeted, specific support.
I do not need to convince you that government has a role to play in supporting autistic Islanders: the supports already in place make it clear that’s understood.
But I do need to convince you that what we are lacking is determined, coordinated, leadership.
Leadership that can transcend departmental boundaries and focus instead on the needs and aspirations the bill speaks to.
Leadership that can seek to weave together our patchwork of programs and services into a cohesive supportive framework.
Hon. Marion Reid, former Lieutenant Government and member of this Assembly, once gave me a valuable piece of advice: when you want government to do something better, she told me, come up with a plan for how it can be done. Don’t just say “you need to make things better,” say “here’s how you can make things better.”
There is, at present, not a single act or regulation in Prince Edward Island that mentions the word autism.
I think it’s time that changed, and I think this bill sets out a reasonable way for that to happen, a reasonable way to make things better: it is not the “wake up jerks and do something about autism act,” it is the “we’re on the right track but it’s time to take a bird’s eye view and work together on this” act.
I sincerely believe that the leadership and coordination that would logically follow can take the good works and goodwill that already exist and build on them.
I believe that having someone around the cabinet table looking at things through what the Hon. Premier might term “an autism lens,” would allow us to ensure that we build a truly autism-friendly Island, an Island that allows our autistic brothers and sisters to thrive.
Thank you.
(The entire debate can be viewed in the November 27, 2018 Hansard).
The Autism Secretariat Act will be debated tonight on the floor of the Legislative Assembly. I’ve been invited by MLA Sidney MacEwen, who put forward the bill, to join him on the floor as a “stranger” when the the Legislative Assembly moves to consider the bill as Committee of the Whole House.
I encourage you to attend the proceedings in the public gallery tonight if you are able, or to tune in to the live stream if you are not. The evening sitting starts at 7:00 p.m.
The Spanish Prisoner, David Mamet’s 1998 film, remains one of my favourites. The movie has a stellar cast that includes Campbell Scott, Steve Martin, Rebecca Pidgeon, Ben Gazzara, Felicity Huffman and Ricky Jay.
Ricky Jay died on Saturday, at the age of 72. The Spanish Prisoner was my first exposure to him, so I knew him as an actor before I knew him as a magician. That was corrected in 2002 when, at the insistence of my friend Dave, we took in his show in New York City.
I was a true fan. He will be missed.
My father’s father was born in Konjsko Brdo, Croatia in 1903; he left for Canada in 1926, and sometime after that my great-grandfather’s family relocated to Dišnik, in northeastern Croatia, a village just north of the city of Kutina.
This fact of my ancestry explains why I’ve visited this small town of some 20,000 people that you’ve never heard of. Twice.
The first time was in October 2004 when my father and I visited as part of a father-and-son exploration of our Croatian roots. At the time we didn’t know of our family’s pilgrimage from Konjsko Brdo, and we’d been led to the area on the off chance that we might locate my father’s cousin Regina Arace, who was rumoured to live there. We didn’t find Regina (although we found her house), but we did find my father’s last surviving aunt, Manda, and her husband Iva Baretic, living in a small house nearby. As I wrote at the time, this was a huge surprise, as we’d no idea that my grandfather had younger siblings:
By some miraculous series of events that involved a trip to a bookie, a trip to the police station (for information, not arrest), and about a dozen extremely helpful Croatians who sent us “up the hill, to the right, until where the pavement ends and you come to a vineyard,” at 4:00 p.m. we found ourselves driving our little Renault down a rough country lane towards a fedora-wearing man leaning on a fence. Dad asked, in his best Croatian, “can you direct us to Manda´s house?”
“This is Manda´s house!” was his response. We had found the house of my step-great-Aunt Manda and her husband Ivo. Manda’s father Stipe is my great-grandfather. We were invited into their humble farmhouse, fed a meal of cured ham and whisky (Dad drank the whisky — I was driving), and Dad pulled off an amazing facsimile of a native Croatian speaker to engage them in conversation about family connections, family history, and their life.
Here’s a photo of Manda, my father, and Ivo:

And here’s me and Manda and her dog:

The experience of discovering long-lost family is and will remain one of the highlights of my traveling life, and, I think, of my father’s as well.
That evening, eager to go back the next day for another visit, we booked a room at the Hotel Kutina, in the nearest town that had a hotel.

The next day we did, indeed, go back, bringing gifts and engaging in some more catch-up about the previous century. And then we were off south, where even more family discoveries awaited us.
Six years later, in December of 2010, I went back to Kutina, this time with Oliver and Catherine.
Our trip had started in Munich, continued to Basel, then Venice, Ljubljana and finally Croatia. We booked ourselves a room at the same Hotel Kutina; it was colder in December than it had been on the first visit in October, and the hotel, if memory serves, was either missing hot water or heat. Or maybe both. But at least there were blankets:

Here’s Oliver and Catherine in front of the hotel:

The next day we went in search of Manda and Ivo; I was eager to introduce Oliver to his great-great-Aunt and her husband, and for Catherine and Oliver to see something of rural Croatia.
To our dismay, while visiting the graveyard in Dišnik we found Ivo’s grave; there was no grave for Manda, however, and we were hopeful that she was still alive.
Through a rather miraculous and circuitous connection involving the Peruvian branch of the Rukavinas, we were able to find Manda in a Red Cross-Red Crescent nursing home nearby. Here’s a photo of Manda and Oliver:

It was a challenging visit: we spoke no Croatian, Manda spoke no English, and by this time she was in advanced stages of dementia. But we all tried our best, and I think the visit brought a little light into all of our lives.
Again bidding farewell to Manda and leaving greater Kutina, we too headed south for more family adventures.
This is all a very long-winded preamble to a brief note that Kutina achieved some small measure of fame in the latest telling of John Le Carré’s The Little Drummer Girl.
In episode 3, Charlie, played by Florence Pugh, is driving a Mercedes from Greece to Austria, and stops in Kutina for the night. She stops at the Hotel Glavina, a hotel that, as far as I can determine, is fictional.
Here’s an (audioless) clip showing Charlie’s arrival in Kutina, and her meetup with an undercover agent:
They go on to play a short game of Scrabble by way of communicating secrets to each other.
One minute and twenty-one seconds of the episode are set in Kutina.
(If you liked this post, check out William Denton’s rigorous cataloging of the appearances of libraries in Archie comics).
The Guardian published a guest opinion piece I wrote on The Autism Secretariat Act, which received first reading in the Legislative Assembly this week.
This bill is a reasonable and straightforward call for the establishment of cabinet-level responsibility for autism; I believe that it’s a small step in the right direction toward coordinating programs and services for autistic Islanders.
It’s been an odd experience to be invested in the passage of a bill to this extent, and I’ve spent a lot of my time this week reaching out to MLAs to try to explain why I feel this way, and to ask them to support the bill.
It’s also odd, of course, to be supporting a bill or forward by a Progressive Conservative member when I’ve no affiliation with the party; but politics, as they say, makes strange bedfellows, and I believe PC MLA Sidney MacEwen has put forward the bill for all the right reasons: he’s talked to constituents, distilled a problem from what they’ve told him, and is proposing a change to address the issue.
I think the plan is for the bill to receive second reading on Tuesday evening; I am hopeful that it will receive all-party support and move forward.
Every morning during the school year I drive Oliver from our house to Colonel Gray Senior High School, a distance of 1.74 km one-way.
Oliver sent me a link to Mission Emission this morning, a calculator for vehicle emissions, and I used it to determine the emissions from this daily school run, which it calculates are 537g of CO2.
Doubling that–because I drive back home immediately afterward on the same route–gives me a figure of 1074g of CO2 per day, or, over 180 school days, 193 kilograms of CO2 per year.
If Oliver and I were to bicycle to school instead of driving, our daily impact would go from 1074g of CO2 to 20g of CO2, which is a dramatic decrease to 3.6 kilograms per year.
Walking to school would achieve a similar although slightly less impressive result, lowering our impact to 7.9 kilograms per year.
Of course, as with all discussions of emissions and climate change, the invisibility of CO2 and the attendant difficulty in imagining what these numbers mean in real terms in our daily life is part of the challenge of behaviour modification: in this regard I found the recent IPCC report incredibly motivating, as it calls for net-zero by 2050, and net-zero emissions is something I can wrap my head around.
Moving from 193 kg of CO to 3.6 of kg is getting pretty close to net-zero: it’s a 98% reduction in emissions for our school run.
This documentary short tells the sad and yet somehow delightful story of the famous IKEA photograph of Amsterdam that appears on walls all around the world.
Filmmaker Tom Roes tracked down the brother of the late Fernando Bengoechea, who took the photograph, and learned the story of how the photo was taken, and how it came to be acquired by IKEA.
The intersection of private detective work, journalism, film-making and YouTube can be a very interesting place indeed.
There’s a little more of the story in this blog post by Roes (and if you’re English-speaking, be sure to turn on subtitles when you watch the documentary).

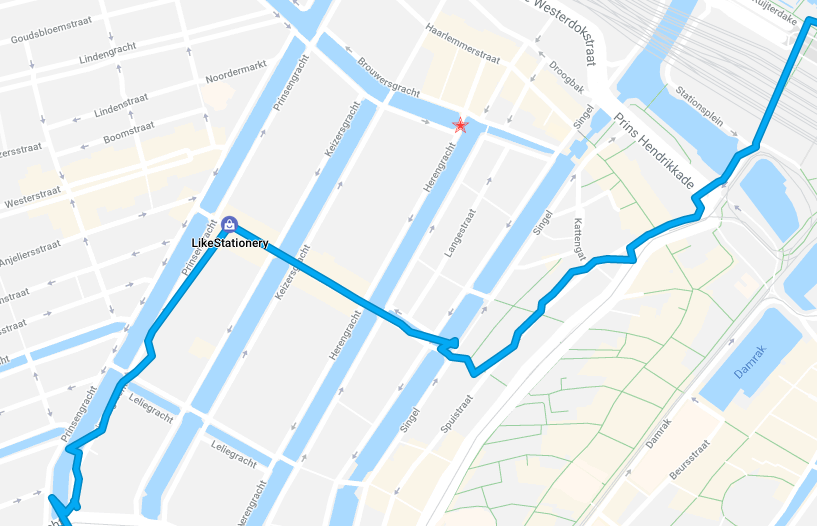
It turns out that when Oliver and I were in Amsterdam in early September we came within a block of the location where the photo was taken; here’s my Google Location History for September 3, 2018, with a red star showing the location near the intersection of Brouwersgracht and Herengracht:
Because this autumn wasn’t already exciting enough, fates connived to cause our roof to start leaking last month. We got by with a temporary patch job and a fleet of buckets in the attic, but the fall rains got the best of us, and I feared a completely meltdown come midwinter or spring thaw.
Fortunately, by some miracle of scheduling and logistics, MacBeth Bros. were able to squeeze in our job last week. Their crew is dynamite: they threaded the needle of roofing through the rain and snow and sleet and they got it done: the front roof went up on Tuesday, the back roof on Thursday, and the vestibules on Friday.

We’ve got more infrastructure work ahead of us this fall, as the roof worked showed up some issues with our chimney, and we have a longstanding job to insulate the attic that we really need to attend to. But we’ve made a good start.
The aforementioned fates, seeing that we’d taken control of things, decided to up the ante and caused our upstairs toilet to leak, which damaged our kitchen ceiling; fortunately this was covered by our PEI Mutual insurance policy, so this work was quickly attended to and the paint went up on the kitchen ceiling on Friday.
In the grander scheme of things we have nothing to complain about: we can afford to pay the bills, we have food on our plates and hot water in our radiators, and we’re ready to take on the winter.
About This Blog
 I am Peter Rukavina and this is my blog. I am a writer, letterpress printer, and a curious person.
I am Peter Rukavina and this is my blog. I am a writer, letterpress printer, and a curious person.
To learn more about me, read my /now, look at my bio, listen to audio I’ve posted, read presentations and speeches I’ve written, see things I’ve favourited elsewhere, or get in touch (peter@rukavina.net is the quickest way).
I have been writing here since May 1999: you can explore the 25+ years of blog posts in the archive.
![]() You can subscribe to an RSS feed of posts, an RSS feed of comments, an RSS feed of favourites elsewhere, or a podcast RSS feed that just contains audio posts. You can also receive a daily digests of posts by email. I also publish an OPML blogroll.
You can subscribe to an RSS feed of posts, an RSS feed of comments, an RSS feed of favourites elsewhere, or a podcast RSS feed that just contains audio posts. You can also receive a daily digests of posts by email. I also publish an OPML blogroll.
Instagram • YouTube • Vimeo • ORCID • OpenStreetMap • Internet Archive • PEI.art • Drupal • Github.