
Since I migrated this blog to a Hetzner server, I’ve been paying attention to the “Graphs” tab of the server dashboard to see how the capacity of the server matches the traffic I’m expecting it to handle.
One of the things I’ve noticed is that there are regular periods of very high CPU usage, periods where the 4 vCPUs are almost maxed out:
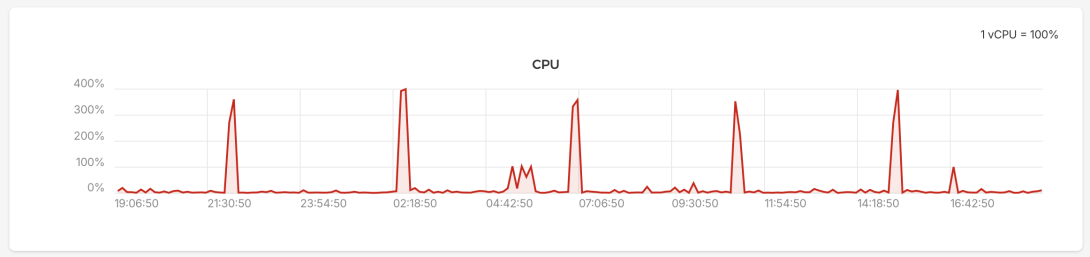
These periods are accompanied by corresponding jumps in network traffic:
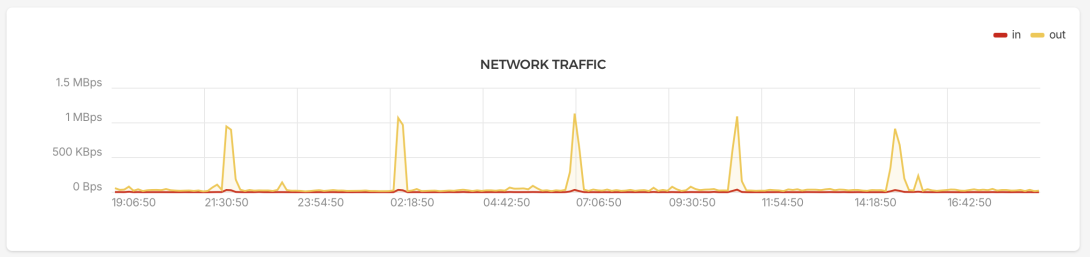
I got curious about what might be causing this, and, because I suspected web traffic bumps, I started by looking at the 20 most popular user-agents in my Apache logfiles, with:
awk -F'"' '{print $6}' access.log | sort | uniq -c | sort -nr | head -20The result:
577651 Scrapy/2.11.2 (+https://scrapy.org)
39018 Mozilla/5.0 (Linux; Android 5.0) AppleWebKit/537.36 (KHTML, like Gecko) Mobile Safari/537.36 (compatible; Bytespider; spider-feedback@bytedance.com)
23216 Mozilla/5.0 (iPhone; CPU iPhone OS 18_5 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/18.5 Mobile/15E148 Safari/604.1
15561 Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36
14793 Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; GPTBot/1.2; +https://openai.com/gptbot)
14571 Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/137.0.0.0 Safari/537.36
12838 Mozilla/5.0 (Linux; Android 10; K) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/137.0.0.0 Mobile Safari/537.36
12306 Mozilla/5.0 (compatible; SemrushBot/7~bl; +http://www.semrush.com/bot.html)
10834 Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/18.5 Safari/605.1.15
9714 Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; ClaudeBot/1.0; +claudebot@anthropic.com)
7104 Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; Amazonbot/0.1; +https://developer.amazon.com/support/amazonbot) Chrome/119.0.6045.214 Safari/537.36
7005 Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; bingbot/2.0; +http://www.bing.com/bingbot.htm) Chrome/116.0.1938.76 Safari/537.36
6287 Wget/1.21.3
5885 meta-externalagent/1.1 (+https://developers.facebook.com/docs/sharing/webmasters/crawler)
5093 Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:139.0) Gecko/20100101 Firefox/139.0
4798 Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/137.0.7151.68 Mobile Safari/537.36 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)
4593 Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36
4143 Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/137.0.0.0 Safari/537.36
3446 -
3228 Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:72.0) Gecko/20100101 Firefox/72.0I asked ChatGPT to normalize and summarize, which gave me:
| Lines | Normalized User-Agent | Type | Notes |
|---|---|---|---|
| 577651 | Scrapy | Bot | Likely automated scraping (Scrapy framework) |
| 39043 | Bytespider | Bot | From ByteDance (TikTok); known aggressive crawler |
| 23337 | Safari on iPhone | Browser | Human traffic, Apple mobile Safari |
| 15590 | Chrome on Linux | Browser | Human or automation (generic Linux desktop Chrome) |
| 14793 | GPTBot | Bot | OpenAI’s web crawler |
| 14571 | Chrome on Windows | Browser | Human or automation (Windows desktop Chrome) |
| 12838 | Chrome on Android | Browser | Human traffic, mobile Chrome |
| 12307 | SemrushBot | Bot | SEO bot from Semrush |
| 10840 | Safari on macOS | Browser | Human traffic |
| 9727 | ClaudeBot | Bot | From Anthropic (AI crawler) |
| 7105 | Amazonbot | Bot | Amazon’s crawler |
| 7018 | Bingbot | Bot | Microsoft’s search indexer |
| 6296 | Wget | Tool | Scripted fetch tool; likely automation or scraping |
| 5891 | Facebook External Agent | Bot | Facebook link preview/crawler bot |
| 5101 | Firefox on Windows | Browser | Human traffic |
| 4798 | Googlebot on Android | Bot | Google’s search bot, disguised as Android browser |
| 4593 | Chrome on Windows | Browser | Redundant with earlier Chrome/Windows |
| 4143 | Chrome on macOS | Browser | Human or automation, Mac desktop |
| 3447 | Unknown (“-”) | Unknown | Empty/missing user-agent |
| 3231 | Firefox on Linux (Ubuntu) | Browser | Human traffic |
It also gave me this summary:
- Total bot/tool traffic: ~695,940 (≈ 85% of top 20 traffic)
- Likely human browser traffic: ~102,296 (≈ 13%)
- Unknown/empty: ~3,447 (≈ 0.4%)
This log has a total of 964,802 lines in it, meaning that whatever “Scrapy” is doing is responsible for 60% of the traffic to my blog.
Ugh.
I followed up by asking ChatGPT to give me a robots.txt file that includes all of the bots, and I’ve added that to this site’s robots.txt (leaving out some friendly user-agents like NetNewsWire).
Because “Scrapy” seems particular evil, I also blocked it at the Apache level, with:
<IfModule mod_rewrite.c>
RewriteEngine On
RewriteCond %{HTTP_USER_AGENT} ^Scrapy [NC]
RewriteRule ^.* - [F,L]
</IfModule>I tested that this was working with:
curl -I -A "Scrapy/2.11.2 (+https://scrapy.org)" https://ruk.caWhich properly returned:
HTTP/1.1 403 Forbidden
Date: Tue, 10 Jun 2025 22:31:15 GMT
Server: Apache/2.4.63 (Fedora Linux) OpenSSL/3.2.4
Content-Type: text/html; charset=iso-8859-1I’ll wait 24 hours to see what effect all this has on network traffic and CPU.
About This Blog
 I am Peter Rukavina and this is my blog. I am a writer, letterpress printer, and a curious person.
I am Peter Rukavina and this is my blog. I am a writer, letterpress printer, and a curious person.
To learn more about me, read my /now, look at my bio, listen to audio I’ve posted, read presentations and speeches I’ve written, see things I’ve favourited elsewhere, or get in touch (peter@rukavina.net is the quickest way).
I have been writing here since May 1999: you can explore the 25+ years of blog posts in the archive.
![]() You can subscribe to an RSS feed of posts, an RSS feed of comments, an RSS feed of favourites elsewhere, or a podcast RSS feed that just contains audio posts. You can also receive a daily digests of posts by email. I also publish an OPML blogroll.
You can subscribe to an RSS feed of posts, an RSS feed of comments, an RSS feed of favourites elsewhere, or a podcast RSS feed that just contains audio posts. You can also receive a daily digests of posts by email. I also publish an OPML blogroll.
Instagram • YouTube • Vimeo • ORCID • OpenStreetMap • Internet Archive • PEI.art • Drupal • Github.
Comments
I keep hearing that the…
I keep hearing that the scrapers ignore robots.txt, so I am eager to see what 24 hours will bring.
Looking my server logs for…
Looking my server logs for hits from the “Scrapy” user-agent, it hasn’t requested the robots.txt in the last week. And since I started to reject traffic from Scrapy, my CPU usage and network traffic have plunged, back to expected normal levels.
Seems like a win. Well done.
Seems like a win. Well done.
Add new comment