
A couple of days ago I wrote about my reverse engineering of the video archives of the Legislative Assembly of Prince Edward Island, and I suggested, at the end, that additional hijinks could now ensue.
When I read How I OCR Hundreds of Hours of Video, I knew that’s where I had to look next: the author of that post, Waldo Jaquith, uses optical character recognition — in essence “getting computers to read the words in images” — with video of the General Assembly of Virginia, to do automated indexing of speakers and bills. I reasoned that a similar approach could be used for Prince Edward Island, as our video here also has lower thirds listing the name of the member speaking.
So I tried it. And it worked! Here’s a walk-through of the toolchain I used, which is adapted from Waldo’s.
The structure of the video archive I outlined earlier lends itself well to grabbing a still frame of video every 10 seconds, from the beginning of each 10-second-long transport stream.
I’ll start by illustrating the process of doing OCR on a single frame, and then run through the automation of the process for an entire part of the day.
Each 10-second transport stream has 306 frames. I don’t need all of those, I just need one, so I use FFmpeg to extract a single JPEG like this, run against this transport stream file.
ffmpeg -ss 1 -i "media_w1108428848_014.ts" -qscale:v 2 -vframes 1 "media_w1108428848_014.jpg"
The result is a JPEG like this:

I only need the area of the frame that includes the “lower third” to do the OCR, so I use ImageMagick to crop this out:
convert "media_w1108428848_014.jpg" -crop 439x60+64+360 +repage -compress none -depth 8 "media_w1108428848_014.tif"
This crops out a 439 pixel by 60 pixel rectangle starting 64 pixels from the left and 360 pixels from the top, this section here:

The lower third is different for members with multiple titles, like the Premier, and back bench members, which is why such a large swath is needed, vertically, to ensure all members’ names can be grabbed.
The resulting TIFF file looks like this:

Next I use ImageMagick again to convert all of the cropped lower thirds to black and white, with:
convert "media_w1108428848_014.tif" -negate -fx '.8*r+.8*g+0*b' -compress none -depth 8 "bw-media_w1108428848_014.tif"
Resulting in black and white images like this:

Now I’m ready to do the OCR, for which, like Waldo, I use Tesseract:
tesseract "bw-media_w1108428848_014.tif" "bw-media_w1108428848_014"
This results in a text file with the converted text:
Hon H Wade Maclauchlan
mmm-‘v
Mun (-1 n1 hI-Anralui l‘nl‘ln nan-Iv
Tesseract did an almost perfect job on the member’s name — Hon. H. Wade MacLauchlan. It missed the periods, but that’s understandable as they got blown out in the conversion to black and white. And it got the fourth letter of the Premier’s last name as a lower case rather than upper case “L”, but, again, the tail on the “L” got blown out by the conversion.
And that’s it, really: grab a frame, crop out the lower third, convert to black and white, OCR.
All I need now is a script to pull a series of transport streams and do this as a batch; this is what I came up with:
#!/bin/bash
DATESTAMP=$1
curl -Ss http://198.167.125.144:1935/leg/mp4:${DATESTAMP}.mp4/playlist.m3u8 > /tmp/playlist.m3u8
IFS=_ array=(`tail -1 /tmp/playlist.m3u8`)
IFS=. array=(${array[1]})
UNIQUEID="${array[0]}"
START=$(expr $(($2 * 6 - 1)))
DURATION=$(expr $(($3 * 6)))
END=$(expr $(($START + $DURATION)))
echo "Getting video for ${DATESTAMP}"
rm -f /tmp/concatentated-video.ts
while [ ${START} -lt ${END} ]; do
echo "Getting chunk ${START}"
PADDED=`printf %03d $START`
echo "Changing to ${PADDED}"
curl -Ss "http://198.167.125.144:1935/leg/mp4:${DATESTAMP}.mp4/media_${UNIQUEID}_${START}.ts" > "ts/media_${UNIQUEID}_${PADDED}.ts"
ffmpeg -ss 1 -i "ts/media_${UNIQUEID}_${PADDED}.ts" -qscale:v 2 -vframes 1 "frames/media_${UNIQUEID}_${PADDED}.jpg"
convert "frames/media_${UNIQUEID}_${PADDED}.jpg" -crop 439x60+64+360 +repage -compress none -depth 8 "cropped/media_${UNIQUEID}_${PADDED}.tif"
convert "cropped/media_${UNIQUEID}_${PADDED}.tif" -negate -fx '.8*r+.8*g+0*b' -compress none -depth 8 "bw/media_${UNIQUEID}_${PADDED}.tif"
tesseract "bw/media_${UNIQUEID}_${PADDED}.tif" "ocr/media_${UNIQUEID}_${PADDED}"
let START=START+1
done
With this script in place, and directories set up for each of the generated files — ts/, frames/, cropped/, bw/ and ocr/ — I’m ready to go, using arguments identical to my earlier script. So, for example, if I want to OCR 90 minutes of the Legislative Assembly from the morning of April 22, 2016, starting at the second minute, I do this:
./get-video.sh 20160422A 2 90
I leave that running for a while, and I end up with an ocr directory filled with OCRed text from each of the transport streams, files that look like this:
, . 1
Hon J Alan Mclsaac
MHn-Jrl (v0 Axul: HIVIHP thi | l'llr‘HF"
and this:
_ 4'
Hon. Allen F. Roac‘h
As Waldo wrote in his post:
Although Tesseract’s OCR is better than anything else out there, it’s also pretty bad, by any practical measurement.
And that’s born out in my experiments: the OCR is pretty good, but it’s not consistent enough to use for anything without some post-processing. And for that, I used the same technique Waldo did, computing the Levenshtein distance between the text from each OCRed frame and a list of Members of the Legislative Assembly.
From the Members page on the Legislative Assembly website, I prepared a CSV containing a row for each member and their party designation, with a couple of additional rows to allow me to react to frames where no member was identified:
Bradley Trivers,C
Bush Dumville,L
Colin LaVie,C
Darlene Compton,C
Hal Perry,L
Hon. Allen F. Roach,L
Hon. Doug W. Currie,L
Hon. Francis (Buck) Watts,N
Hon. H. Wade MacLaughlan,L
Hon. Heath MacDonald,L
Hon. J. Alan McIsaac,L
Hon. Jamie Fox,C
Hon. Paula Biggar,L
Hon. Richard Brown,L
Hon. Robert L. Henderson,L
Hon. Robert Mitchell,L
Hon. Tina Mundy,L
James Aylward,C
Janice Sherry,L
Jordan Brown,L
Kathleen Casey,L
Matthew MacKay,C
Pat Murphy,L
Peter Bevan-Baker,G
Sidney MacEwen,C
Sonny Gallant,L
Steven Myers,C
None,N
2nd Session,N
The idea is that for each OCRed frame I take the text and compare it to each of the names on this list; the name on the list with the lowest Levenshtein distance value is the likeliest speaker.
For example, for this OCRed text:
e'b
Hon. Paula Blggav
I get this set of Levenshtein distances:
Bradley Trivers -> 20
Bush Dumville -> 18
Colin LaVie -> 18
Darlene Compton -> 20
Hal Perry -> 17
Hon. Allen F. Roach -> 18
Hon. Doug W. Currie -> 18
Hon. Francis (Buck) Watts -> 22
Hon. H. Wade MacLaughlan -> 19
Hon. Heath MacDonald -> 19
Hon. J. Alan McIsaac -> 17
Hon. Jamie Fox -> 16
Hon. Paula Biggar -> 8
Hon. Richard Brown -> 17
Hon. Robert L. Henderson -> 22
Hon. Robert Mitchell -> 20
Hon. Tina Mundy -> 16
James Aylward -> 19
Janice Sherry -> 19
Jordan Brown -> 17
Kathleen Casey -> 18
Matthew MacKay -> 18
Pat Murphy -> 18
Peter Bevan-Baker -> 19
Sidney MacEwen -> 19
Sonny Gallant -> 17
Steven Myers -> 19
None -> 19
2nd Session -> 20
The smallest Levenshtein distances is Hon. Paula Biggar, with a value of 8, so that’s the value I connect with this frame.
Ninety minutes of video from Friday morning results in 540 frame captures and 540 OCRed snippets of text.
With the snippets of text extracted, I run a PHP script on the result, dumping out an HTML file with a thumbnail for each frame, coloured to match the party of the member speaking I identified from the OCR:
<?php
$colors = array("L" => "#F00", // Liberal
"C" => "#00F", // Conservative
"G" => "#0F0", // Green
"N" => "#FFF" // None
);
$names = file_get_contents("member-names.txt");
$members = explode("\n", $names);
foreach ($members as $key => $value) {
if ($value != '') {
list($name, $party) = explode(",", $value);
$p = array("name" => $name, "party" => $party);
$m[] = $p;
}
}
$fp = fopen("index.html", "w");
if ($handle = opendir('./ocr')) {
while (false !== ($entry = readdir($handle))) {
if ($entry != "." && $entry != ".." && $entry != '.DS_Store') {
$ocr = file_get_contents("./ocr/" . $entry);
$jpeg = "frames/" . basename($entry, ".txt") . ".jpg";
$ts = "ts/" . basename($entry, ".txt") . ".ts";
$ocr = preg_replace('/[^a-z\n]+/i', ' ', $ocr);
$mindist = 9999;
unset($found);
foreach($m as $key => $value) {
if ($value != '') {
$d = levenshtein($value['name'], trim($ocr));
if ($d < $mindist) {
$mindist = $d;
$found = $value;
}
}
}
fwrite($fp, "<div style='float: left; background: " . $colors[$found['party' . "'>\n");
fwrite($fp, "<a href='$ts'><img src='$jpeg' style='width: 64px; height: auto; padding: 5px'></a></div>");
}
}
closedir($handle);
}
The resulting HTML file looks like this in a browser:

The frames that are coloured white are frames where there was either no lower third, or where the lower third didn’t contain the name of the member speaking. It’s not a perfect process: the last dozen frames or so, for example, are from the consideration of the estimates, where there’s no member’s name in the lower third, but my script doesn’t know that, and it simply finds the member’s name with the smallest Levenshtein distance from the jumble of text it does find there; some fine-tuning of the matching process could avoid this.
Changing the output of the PHP script so that the names of the members are included, the thumbnails a little larger, and each thumbnail linked to the transport stream of the associated video, and I get a visual navigator for the morning’s video:

One more experiment, this time representing each OCRed frame as a two-pixel-wide part of a bar, allowing the entire morning to be visualized by party:

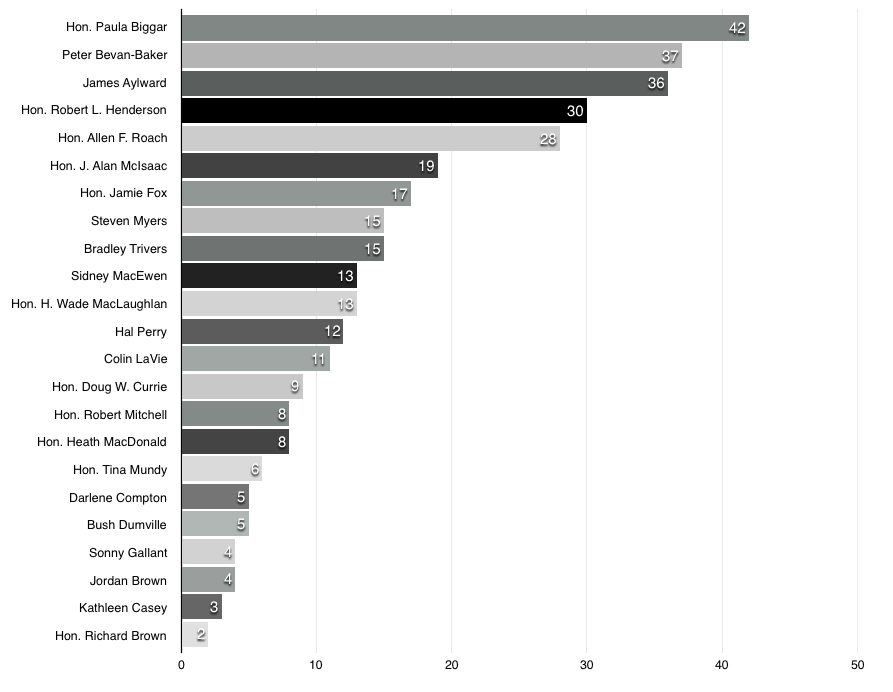
Leaving thumbnails and party colours out of it completely, here are the members ranked by the number (of the total 504) 10 second frame captures they appear in the first frame of (the total is not 540 because the remaining frames had no lower third and thus no identified speaker):
42 Hon. Paula Biggar
37 Peter Bevan-Baker
36 James Aylward
30 Hon. Robert L. Henderson
28 Hon. Allen F. Roach
19 Hon. J. Alan McIsaac
17 Hon. Jamie Fox
15 Steven Myers
15 Bradley Trivers
13 Sidney MacEwen
13 Hon. H. Wade MacLaughlan
12 Hal Perry
11 Colin LaVie
9 Hon. Doug W. Currie
8 Hon. Robert Mitchell
8 Hon. Heath MacDonald
6 Hon. Tina Mundy
5 Darlene Compton
5 Bush Dumville
4 Sonny Gallant
4 Jordan Brown
3 Kathleen Casey
2 Hon. Richard Brown
Visualized as a bar chart, this data looks like this:
And finally, here’s a party breakdown (it’s important to note that this is only a very rough take on the “which party gets the most speaking time” question because I’m only looking at the first frame of every 10 second video chunk):
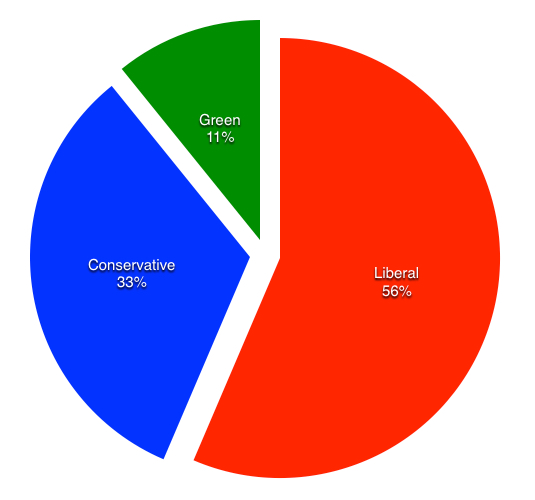
Peter Bevan-Baker, Leader of the Green Party, is the only speaker in the Green slice; he’s the second-most-frequent speaker — 37 frame chunks — but the other parties spread their speaking across more members which is why the Green Party only represents 11% of the frame chunks in total.
As with much of the information that public bodies emit, the Legislative Assembly of PEI could make this sort of analysis much easier by releasing time-coded open data in addition to the video — as sort of “structured data Hansard,” if you well. Without that, we’re left to using blunt instruments like OCR which, though fun, involve a lot of futzing that should really be required.
About This Blog
 I am Peter Rukavina and this is my blog. I am a writer, letterpress printer, and a curious person.
I am Peter Rukavina and this is my blog. I am a writer, letterpress printer, and a curious person.
To learn more about me, read my /now, look at my bio, listen to audio I’ve posted, read presentations and speeches I’ve written, see things I’ve favourited elsewhere, or get in touch (peter@rukavina.net is the quickest way).
I have been writing here since May 1999: you can explore the 25+ years of blog posts in the archive.
![]() You can subscribe to an RSS feed of posts, an RSS feed of comments, an RSS feed of favourites elsewhere, or a podcast RSS feed that just contains audio posts. You can also receive a daily digests of posts by email. I also publish an OPML blogroll.
You can subscribe to an RSS feed of posts, an RSS feed of comments, an RSS feed of favourites elsewhere, or a podcast RSS feed that just contains audio posts. You can also receive a daily digests of posts by email. I also publish an OPML blogroll.
Instagram • YouTube • Vimeo • ORCID • OpenStreetMap • Internet Archive • PEI.art • Drupal • Github.
Comments
Very cool. You continue to
Very cool. You continue to amaze me - not only in figuring this all out - but in explaining it step by step.
Cool. Does the PEI Assembly
Cool. Does the PEI Assembly publish transcripts that contain time references? Then you could likely cross reference it with video, and make the video searchable that way, and vice versa add video to the transcripts.
Unfortunately not. There is a
Unfortunately not. There is a Hansard, but it is not time-coded. That said, if the video OCR was reliable enough, it might be possible to match the two simply by speaker order.
A helpful commenter on
A helpful commenter on Facebook pointed out that I have have the Premier’s last name as MacLaughlan in my list of canonical member names, which is entirely on me — something went wrong somewhere, likely because of overzealous spell correct.
Nice project Peter. You can
Nice project Peter. You can improve the OCR result if you use some extra switches with tesseract. After some trial and error here are some switches ... convert to grayscale, reduce the number of colours, increase the size and density of the image and sharpen it. I converted to png.
convert media_w1108428848_014.jpg -colorspace Gray -colors 64 -density 500 -resize 250% -sharpen 4 -quality 100 test2.png
and run the resulting png through tesseract.
tesseract test2.png test2
and if you view the resulting test2.txt file you get this:
Hon. H. Wade MacLauchlan
Premier
Minister 0' Justice and Public Saicty
and Attorney General
LIBERAL
Still some errors.
Don
Should have been ... "use
Should have been ... "use some extra switches with convert".
dm
Add new comment